스파크 구조적 연산에서 표현식을 만드는 방법을 알아보자.
1. API는 어디서 찾을까
데이터 변환용 함수는 다음과 같은 곳에서 찾을 수 있다.
- DataFrame 메서드
- DataFrameStateFunctions, DataFrameNaFunctions 등 Dataset 하위 모듈이 다양한 메서드를 제공한다. DataFrame은 Row 타입을 가진 DataSet이다.
- Column 메서드
- Column은 컬럼과 관련된 메서드들을 제공한다. org.apache.spark.sql.functions 패키지는 데이터 타입에 대한 함수들을 제공한다.
본문의 예제에선 다음과 같이 생성한 데이터프래임을 사용한다
1
2
3
4
5
6
7
df = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("/retail-data.csv")
df.printSchema()
df.createOrReplaceTempView("retail_data")
2. 스파크 데이터 타입으로 변환하기
언어 고유 타입을 스파크 데이터 타입으로 변환하기 위해서 lit 함수를 사용한다
1
2
3
from pyspark.sql.functions import lit
df.select(lit(5), lit("five"), lit(5.0))
3. 불리언 데이터 타입 다루기
and, or, true, false로 구성된 불리언 구문을 사용해 논리 문법을 만들 수 있다. 논리 문법을 이용하면 데이터 로우를 필터링 조건을 판별할 수 있다.
1
2
3
4
5
6
7
8
from pyspark.sql.functions import col
df.where(col("InvoiceNo") != '536365')\
.select("InvoiceNo", "Description")\
.show(5, False)
df.where("InvoiceNo <> 536365")\
.show(5, False)
만약 여러 조건에 대한 필터링을 차례대로 적용한다면, 내부적으로 and 구문을 이용해 하나의 문장으로 변환한다, 그러나 or은 반드시 동일한 구문에 조건을 정리해야 한다.
1
2
3
4
5
6
7
8
9
from pyspark.sql.functions import instr
price_filter = col("UnitPrice") > 600
# instr은 주어진 문자열에서 지정된 문자열이 처음으로 나타나는 위치 반환
descrip_filter = instr(df.Description, "POSTAGE") >= 1
df.where(df.StockCode.isin("DOT"))\
.where(price_filter | descrip_filter)\
.show()
Boolean 컬럼을 이용해 DataFrame을 필터링할 수도 있다
1
2
3
4
5
6
7
8
9
10
from pyspark.sql.functions import instr
DOT_code_filter = col("StockCode") == "DOT"
price_filter = col("UnitPrice") > 600
descrip_filter = instr(col("Description"), "POSTAGE") >= 1
df.withColumn("isExpensive", DOT_code_filter & (price_filter | descrip_filter))\
.where("isExpensive")\
.select("unitPrice", "isExpensive")\
.show(5)
4. 수치형 데이터 타입 다루기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from pyspark.sql.functions import expr, pow
# n^r을 pow(n, r)로 구할 수 있다.
fabricated_quantity = pow(col("Quantity") * col("UnitPrice"), 2) + 5
df.select(expr("CustomerId"), fabricated_quantity.alias("realQuantity"))\
.show(5)
from pyspark.sql.functions import lit, round, bround
# round 반올림 기준은 사사오입이다. bround는 소수점을 그냥 생략한다
df.select(round(lit("2.5")), bround(lit("2.5")))\
.show(5)
from pyspark.sql.functions import corr
# corr은 두 컬럼 사이의 상관관계인 피어슨 산관계수를 계산한다.
df.stat.corr("Quantity", "UnitPrice")
df.select(corr("Quantity", "UnitPrice"))\
.show()
# describe()는 컬럼들에 대한 집계(count), 평균(mean), 표준편차(stddev)
# 최솟값(min), 최댓값(max)을 계산한다
df.describe().show()
StatFunctions 패키지는 다양한 통계 함수를 제공한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
old_name = 'UnitPrice'
quantile_probs = [0.5]
rel_error = 0.05
# 백분위수 계산
df.stat.approxQuantile("UnitPrice", quantile_probs, rel_error)
# 교차표(cross-tabulation)나 자주 사용하는 항목 쌍을 확인한다
df.stat.crosstab("StockCode", "Quantity").show()
df.stat.freqItems(["StockCode", "Quantity"]).show()
# 모든 로우에 고유 ID 값을 추가한다
from pyspark.sql.functions import monotonically_increasing_id
df.select(monotonically_increasing_id()).show(2)
5. 문자열 데이터 타입 다루기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from pyspark.sql.functions import initcap
# 주어진 문자열을 공백 단위로 나누고, 모든 단어 첫 글자를 대문자로 변환한다
df.select(initcap(col("Description"))).show()
from pyspark.sql.functions import lower, upper
# lower 함수는 문자열을 소문자로, upper 함수는 대문자로 변환
df.select(col("Description"), lower(col("Description")), upper(lower(col("Description")))).show(2)
from pyspark.sql.functions import lit, ltrim, rtrim, rpad, lpad, trim
df.select(
ltrim(lit(" Hello ")).alias("ltrim"), # "Hello "
rtrim(lit(" Hello ")).alias("rtrim"), # " Hello"
trim(lit(" Hello ")).alias("trim"), # "Hello"
lpad(lit("HELLO"), 3, " ").alias("lp"), # "HEL" 문자열 길이가 두 번째 숫자 인자 이상이면 오른쪽 부터 자른다
rpad(lit("HELLO"), 10, " ").alias("rp") # "HELLO " 문자열 길이가 두 번째 숫자 인자 이상이면 왼쪽부터 자른다
).show(2)
5.1
스파크는 자바 정규 표현식을 사용한다
1
2
3
4
5
6
7
8
from pyspark.sql.functions import instr
# instr 함수를 이용해 특정 값의 존재 여부를 판단한다
contains_black = instr(col("Description"), "BLACK") >= 1
contains_white = instr(col("Description"), "WHITE") >= 1
df.withColumn("hasSimpleColor", contains_black | contains_white)\
.where("hasSimpleColor")\
.select("Description")\
.show(3, False)
locate 함수를 이용하면 지정분 문자열이 처음으로 나타나는 위치를 찾을 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from pyspark.sql.functions import expr, locate
simple_colors = ["black", "white", "red", "green", "blue"]
def color_locator(column, color_string):
return locate(color_string.upper(), column)\
.cast("boolean")\
.alias("is_" + color_string)
selected_columns = [color_locator(df.Description, c) for c in simple_colors]
selected_columns.append(expr("*"))
df.select(*selected_columns)\
.where(expr("is_white OR is_red"))\
.select("Description")\
.show(3, False)
6. 날짜와 타임스탬프 데이터 타입 다루기
스파크는 달력 형태의 date 타입과 날짜와 시간 정보를 모두 가지는 timestamp로 시간 정보를 관리한다. inferSchema 옵션이 활성화 되어 있다면, 스파크는 특정 날짜 포맷을 명시하지 않아도, 날짜를 식별하고 읽을 수 있다.
스파크 TimestampType은 초 단위 정밀도를 제공한다. 따라서 그 이하의 정밀도를 원한다면 Long 데이터 타입으로 데이터를 변환해 사용해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from pyspark.sql.functions import current_date, current_timestamp
date_df = spark.range(10)\
.withColumn("today", current_date())\
.withColumn("now", current_timestamp())
date_df.createOrReplaceTempView("dateTable")
date_df.printSchema()
from pyspark.sql.functions import date_add, date_sub
date_df.select(
col("today"),
date_sub(col("today"), 5), # 5일 이전
date_add(col("today"), 5) # 5일 이후
).show(1)
from pyspark.sql.functions import datediff, months_between, to_date
date_df.withColumn("week_ago", date_sub(col("today"), 7))\
.select(datediff(col("week_ago"), col("today")))\ # 두 날짜 차이
.show(1)
date_df.select(
to_date(lit("2016-01-01")).alias("start"),\ # to_date()는 문자열을 날짜로 변환하는 함수
to_date(lit("2017-05-22")).alias("end")
)\
.select(months_between(col("start"), col("end")))\ # 두 날짜 사이 개월 수
.show(1)
스파크는 날짜를 파싱할 수 없으면 null을 반환하고, 파싱이 되더라고 데이터가 잘못되었는지 판단할 수 없다. 이런 문제를 피하기 위해 to_date 함수와 to_timestamp 함수를 사용할 때 포맷을 지정해 사용할 수 있다. to_date 사용 시 포맷 지정은 옵션이고, to_timestamp는 필수이다.
1
2
3
4
5
6
7
8
9
10
from pyspark.sql.functions import to_date, to_timestamp
date_format = 'yyyy-dd-MM'
date_df = spark.range(1).select(
# 입력의 포맷은 yyyy-dd-MM이고, 이를 파이썬 date 포맷인 yyyy-MM-dd로 변환
to_date(lit("2017-12-11"), date_format).alias("date")
).show()
date_df.select(to_timestamp(col("date"), date_format))\
show()
올바른 날짜 포맷을 사용한다면 다음과 같이 비교를 할 수 있다.
1
date_df.filter(col("date") > lit("2017-12-12")).show()
7. null 값 다루기
스파크에서 잆는 데이터를 표현할 때 null을 사용해야 최적화를 진행할 수 있다. Null은 기본적으로 DataFrame의 하위 패키지인 .na를 사용해 다룬다.
7.1 coalesce
1
2
3
from pyspark.sql.functions import coalesce, col
# coalesce는 인자로 준 컬럼의 데이터 중 null이 아닌 첫 번째 컬럼 값을 반환한다.
df.select(coalesce(col("Description"), col("CustomerId"))).show()
7.2 ifnull, nullIf, nvl, nvl2
coalesce 함수와 유사한 결과를 얻을 수 있는 함수의 종류와 사용법은 다음과 같다.
1
2
3
4
5
6
7
8
9
spark.sql('''
select
ifnull(null, 'return_value'), -- 1st 인자가 null이면 2nd 인자 반환
nullif('value', 'value'), -- 두 인자가 같으면 null, 다르면 1st 인자 반환
nvl(null, 'return_value'), -- 1st 인자가 null이면 2nd 인자 반환
nvl2('not_null', 'return_value', 'else_value') -- 1st 인자가 null아 아니면 2nd 인자 반환, null이면 3th 인자 반환
from retail_data
limit 1
''').display()
7.3 drop
null 값을 가진 로우를 제거하는 함수이다.
1
2
3
4
df.na.drop() # null을 가진 모든 로우를 제거한다.
df.na_drop('any') # 로우 컬럼값 중 하나라도 null 값을 가지면 해당 로우를 제거
df.na.drop('all') # 모든 컬럼의 값이 null이거나 NaN인 경우 로우를 제거
df.na.drop('all', subset=["StockCode", "InvoiceNo"]) # 컬럼을 배열 형태로 넘길 수도 있다
7.4 fill
하나 이상의 컬럼을 특정 값으로 채울 수 있다. 채워 넣을 값과 컬럼으로 구성된 맵을 인수로 사용한다
1
2
3
4
5
6
7
# String 데이터 타입의 컬럼에 존재하는 null 값을 다른 값으로 채운다
df.na.fill("All Null values become this string")
# 다수 컬럼에 특적 값을 채울 수도 있다
df.na.fill("all", subset=["StockCode", "InvoiceNo"])
# 컬럼 별로 null 대신 채울 값을 지정
fill_cols_vals = {"StockCode": 5, "Description": "No Value"}
df.na.fill(fill_cols_vals)
7.5 replace
1
2
# replace(변경 될 값, 변경 후 값, 변경할 컬럼)
df.na.replace([""], ["UNKOWN"], "Description")
8. 정렬하기
asc_nulls_first, desc_nulls_first, asc_nulls_last, desc_nulls_last 함수를 이용해 null 값이 표시되는 기준을 지정할 수 있다.
9. 복합 데이터 타입 다루기
복합 데이터 타입(구조체, 배열, 맵)을 사용해서 상황에 적합한 방식으로 데이터를 구성하고 구조화 할 수 있다.
9.1 구조체
구조체는 DataFrame 내부의 DataFrame 이라고 생각할 수 있다. 다음과 같이 여러 컬럼을 묶어서 구조체를 만들고 조회할 수 있다.
1
2
3
4
5
6
7
8
9
from pyspark.sql.functions import struct, col
# 다수의 컬럼을 묶어서 구조체를 만든다
complex_df = df.select(struct("Description", "InvoiceNo").alias("complex"))
complex_df.createOrReplaceTempView("complex_df")
# struct 데이터를 조회하는 방법
complex_df.select("complex.Description").display()
complex_df.select(col("complex").getField("Description")).display()
9.2 배열
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from pyspark.sql.functions import split, size, array_contains, explode, col
# 선택한 컬럼의 데이터를 구분자(2번째 인자)를 기준으로
# 합쳐서 하나의 배열로 변환한다
df.select(split(col("Description"), " ")).show(2)
# 복합 데이터 타입을 또 다른 컬럼처럼 다룰 수 있게 한다.
df.select(split(col("Description"), " ").alias("array_col"))\
.selectExpr("array_col[0]")\
.show(2)
# 배열 크기 조회
df.select(size(split(col("Description"), " "))).show(2)
# 특정 값이 존재하는지 확인
df.select(array_contains(split(col("Description"), " "), "WHITE")).show(2)
# 배열 타입의 컬럼을 입력받아서, 배열의 각 값을 로우로 변환한다
df.withColumn("splitted", split(col("Description"), " "))\
.withColumn("exploded", explode(col("splitted")))\
.select("Description", "InvoiceNo", "exploded")\
.show(2)
9.3 맵
맵은 map 함수와 key-value 쌍을 이용해 생성한다
1
2
3
4
5
6
7
8
9
10
11
12
13
from pyspark.sql.functions import create_map
# map 생성
my_map = create_map(col("Description"), col("InvoiceNo")).alias("complex_map")
df.select(my_map).show(2)
# 값 선택
df.select(my_map)\
.selectExpr("complex_map['WHITE METAL LANTERN']")\
.show(2)
# map 타입을 분해해서 컬럼으로 변환
df.select(my_map)\
.selectExpr("explode(complex_map)")\
.show(2)
10. JSON 다루기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from pyspark.sql.functions import get_json_object, json_tuple, to_json, from_json
from pyspark.sql.types import *
json_df = spark.range(1)\
.selectExpr("""
'{"myJSONKey"; {"myJSONValue": [1, 2, 3]}}'
as jsonString
""")
# get_json_object로 JSON객체를 인라인 쿼리로 조회할 수 있다.
# depth가 1인 JSON 객체는 json_tuple을 사용할 수 있다
json_df.select(
get_json_object(col("jsonString"), "$.myJsonKey.myJSONValue[1]").alias("column"),
json_tuple(col("jsonString"), "myJSONKey")
).show(2)
# to_json을 이용해 StructType을 JSON문자열로 변경할 수 있다.
df.selectExpr("(InvoiceNo, Description) as my_struct")\
.select(to_json(col("my_struct")))
parse_schema = StructType((
StructField("InvoiceNo", StringType(), True),
StructField("Description", StringType(), True)
))
# to_json 함수는 JSON 데이터소스와 동일한 형태의 맵을 파라미터로 사용할 수 있다
# from_json을 사용하면 문자열을 다시 객체로 변환할 수 있다. 파라미터로 스키마를 지적해줘야 한다.
df.selectExpr("(InvoiceNo, Description) as my_struct")\
.select(to_json(col("my_struct")).alias("new_json"))\
.select(from_json(col("new_json"), parse_schema), col("new_json")).show(2)
11. 사용자 정의 함수(UDF - User Defined Function)
UDF는 사용자가 원하는 형태의 트랜스포메이션을 만들 수 있게 해준다. 하나 이상의 컬럼을 입력받고, 반환할 수 있다. UDF는 특정 SparkSession이나 Context에서 사용할 수 있게 임시 함수형태로 등록된다.
UDF를 사용하는 방법은 다음과 같다.
- UDF를 정의한다
- 정의한 함수를 모든 워커 노드가 사용할 수 있게 스파크에 등록하낟. 스파크는 드라이버에서 함수를 직렬화하고, 네트워크를 통해 모든 executor process로 전달한다.
- 전달된 함수는 언어에 따라 다음과 같이 동작 방식이 다르다
- 스칼라와 자바의 경우 JVM 환경에서만 사용할 수 있다. 때문에 스파크 내장 함수가 제공하는 코드 생성 기능을 사용할 수 없어서 약간의 성능 저하가 발생하낟.
- 파이썬의 경우 워커 노드에서 파이썬 프로세스를 실행해 파이썬이 이해할 수 있는 포맷으로 데이터를 직렬화한다. 그 후, 각 데이터 로우마다 함수를 실행하고, JVM과 스파크에 처리 결과를 반환한다. 이를 도식화하면 다음과 같다.
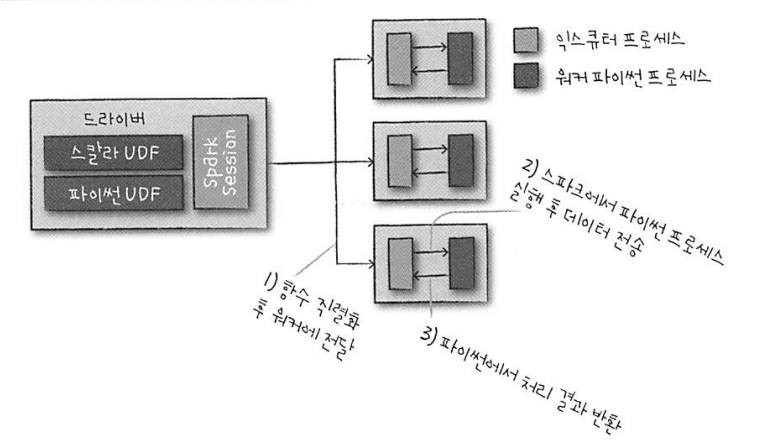
1
2
3
4
5
6
7
8
9
10
11
12
from pyspark.sql.functions import udf
def power3(double_value):
return double_value ** 3
# udf 등록
power3_udf = udf(power3)
df.select(power3_udf(col("UnitPrice"))).show(2)
# spark SQL 함수로 UDF를 등록하면 SQL에서 UDF를 사용할 수 있다.
spark.udf.register("power3", power3)
df.selectExpr("power3(UnitPrice)").show(2)
출처 - 스파크 완벽 가이드