자바 가비지 수집의 요체는 시스템에 있는 모든 객체의 수명을 정확히 몰라도 런타임이 대신 객체를 추적하며 쓸모없는 객체를 알아서 제거하는 것이다. 모든 가비지 수집 구현체는 다음과 같은 원칙을 지켜야 한다.
- 알고리즘은 반드시 모든 가비지를 수집해야 한다.
- 살아 있는 객체는 절대로 수집해선 안된다.
- segmentation fault 방지
mark and sweep
자바의 가비지 수집은 기본적으로 mark and sweep이라는 알고리즘을 사용한다. 가장 단순한 mark and sweep 알고리즘의 경우 아직 회수되지 않은 객체를 가리키는 포인트를 포함하는 allocated list를 사용한다. 전체적인 알고리즘은 다음과 같다.
- 할당 리스트를 순회하면서 마크 비트를 지운다
- GC 루트부터 살아 있는 객체를 찾는다
- DFS를 사용한다.
- 이렇게 해서 생성된 그래프를 라이브 객체 그래프라고 한다.
- 찾은 객체마다 마크 비트를 세팅한다
- allocated list를 순회하면서 마크 비트가 세팅되지 않은 객체를 찾는다
- 힙에서 메모리를 회수해 free list에 넣는다
- allocated list에서 객체를 삭제한다
가비지 수집 용어
GC 알고리즘을 이해하기 위해 필요한 용어는 다음과 같다.
- STW(Stop The World)
- GC 사이클이 발생해 가비지를 수집하는 동안에 모든 애프리케이션 스레드를 중단하는 것
- 동시
- GC 스레드는 애플리케이션 스레드와 동시 실행될 수 있다. 이는 계산 비용 면에서 비싸고 어려운 작업이다. 또 한, 100% 동시 실행을 보장하는 알고리즘도 없다.
- 병렬
- 여러 스레드를 동원해서 가비지 수집을 한다
- 정확
- 정확한 GC 스킴은 전체 가비지를 한 번에 수집할 수 있게 힙 상태에 관한 충분한 타입 정보를 가지고 있다.
- 보수
- 보수적인 스킴은 정확한 스킴의 정보가 없다. 때문에 리소스를 자주 낭비하고 타입 체계를 무시한다.
- 이동
- 이동 수집기에서 객체의 메모리 주소는 고정적이지 않다. 때문에 C++처럼 raw pointer로 직접 접근할 수 있는 환경과 잘 맞지 않는다.
- 압착
- 살아남은 객체들은 GC 사이클 마지막에 연속된 단일 영역으로 배열된다. 그리고 객체 쓰기가 가능한 여백의 시작점을 가리키는 포인터가 존재한다. 압착 수집기는 메모리 단편화를 방지한다.
- 방출
- 수집 사이클 마지막에 할당된 영역을 완전히 비우고 살아남은 객체는 모두 다른 메모리 영역으로 방출한다.
핫스팟 런타임 개요
객체를 런타임에 표현하는 방법
핫스팟은 런타임에 oop(Ordinary Object Pointer)라는 구조체로 객체를 나타낸다. Oop class의 필드 부분은 각 다음과 같은 정보를 가진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
// Oop represents the superclass for all types of
// objects in the HotSpot object heap.
public class Oop {
static {
VM.registerVMInitializedObserver(new Observer() {
public void update(Observable o, Object data) {
initialize(VM.getVM().getTypeDataBase());
}
});
}
private static synchronized void initialize(TypeDataBase db) throws WrongTypeException {
Type type = db.lookupType("oopDesc");
mark = new CIntField(type.getCIntegerField("_mark"), 0);
klass = new MetadataField(type.getAddressField("_metadata._klass"), 0);
compressedKlass = new NarrowKlassField(type.getAddressField("_metadata._compressed_klass"), 0);
headerSize = type.getSize();
}
/**
* 사용하는 주소가 "특별"하며 VM에 의해 업데이트 된다는 것을 나타낸다.
* 현재 VM에서 리플렉션 구현을 위해 사용된다.
*/
private OopHandle handle;
/**
* VM에 존재하는 모든 generation을 추상화한 타입
* 존재하는 모든 객체와 클래스에 접근할 수 있다.
* JVM이 객체를 할당하고 관리하는 힙 영역을 나타낸다.
* 객체가 메모리에 할당되고 반환될때 사용된다.
*/
private ObjectHeap heap;
Oop(OopHandle handle, ObjectHeap heap) {
this.handle = handle;
this.heap = heap;
}
private static long headerSize;
private static CIntField mark; // GC에서 사용되는 마킹 정보
private static MetadataField klass; // 클래스에 대한 정보를 저장한다
/**
* NarrowKlassFiel는 MetadataField를 extends하고 있다.
* JVM 메모리 효율을 높이기 위해 클래스에 대한 포인터를 압축해 저장한다.
*/
private static NarrowKlassField compressedKlass;
oop는 자바 메서드의 스택 프레임으로부터 자바 힙을 구형하는 메모리 내부를 카르킨다. hotspot은 내부적으로 Oop를 이용해 여러 자료구조를 정의한다. 그 중 Instance는 자바 클래스의 인스턴스를 나타낸다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// An Instance is an instance of a Java Class
public class Instance extends Oop {
static {
VM.registerVMInitializedObserver(new Observer() {
public void update(Observable o, Object data) {
initialize(VM.getVM().getTypeDataBase());
}
});
}
private static long typeSize;
private static synchronized void initialize(TypeDataBase db) throws WrongTypeException {
Type type = db.lookupType("instanceOopDesc");
typeSize = type.getSize();
}
Instance(OopHandle handle, ObjectHeap heap) {
super(handle, heap);
}
...
}
instanceOop의 메모리 레이아웃은 기계어 워드 2개로 구성된 헤더로 시작한다. Mark 워드(인스턴스 관련 메타데이터를 가리키는 포인터) 다음에 Klass 워드(클래스 메타데이터를 가리키는 포인터)가 나온다. 자바 7까지는 instanceOop의 Klass 워드가 자바 힙에 있는 PemGen이라는 메모리 영역을 가리켰다. 자바 힙에 있는 것들은 객체 헤더를 가져야 하기 때문에 KlassOop로 메타데이터를 참조했다. 그러나 자바 8부터 Klass(클래스에 관련된 정보를 저장하는 클래스. JVM 내부에서 클래스 메타데이터와 관련된 정보를 저장하고 클래스의 동작과 상호작용을 지원한다)가 자바 힙의 주 영역 밖으로 빠졌기 때문에 Klass 워드가 자바 힙 밖을 가리킨다. 때문에 객체 헤더가 필요 없다. oop는 대부분 기계어 워드라서 프로세서 비트를 따른다. 이런 구조는 메모리를 크게 낭비할 수 있어서 메모리를 절약할 수 있는 방법을 제공한다. 이를 압축 oop(compressed oop)라고 한다. 압축 oop를 사용하기 위해선 다음 옵션을 주면 된다.
1
-XX:+UserCompressedOops
compressed oop는 힙에 있는 다음과 같은 oop를 압축한다.
- 힙에 있는 모든 객체의 klass 워드
- 참조형 인스턴스 필드
- 객체 배열의 각 원소
핫스팟 객체 헤더는 다음과 같이 구성된다.
- Mark 워드 (32비트 환경이면 4바이트, 64바이트 환경이면 8바이트)
- Klass 워드 (압축됐을 수 있다)
- 객체가 배열이면 length 워드(항상 32비트)
- 자바에서 배열은 객체이며 length 길이 제한 때문에 자바 배열은 32비트로 제한된다.
- 32비트 여백 (정렬 규칙 때문에 필요한 경우)
JVM 환경에서 자바 레퍼런스는 instanceOop 또는 null만을 가리킬 수 있다. 이는 다음과 같은 의미를 갖는다.
- 자바 값은 기본형 값 또는 instanceOop 주소에 대응되는 비트 패턴이다.
- 모든 자바 레퍼런스는 자바 힙의 주 영역에 있는 주소를 가리키는 포인터이다.
- 자바 레퍼런스가 가리키는 주소에는 Mark word + Klass word가 들어있다.
- KlassOop와 Class<?> 인스턴스는 다르며 (klassOop는 힙의 메타데이터 영역에 있다) KlassOop를 자바 변수 안에 넣을 수 없다.
핫스팟 oop 전체 상속 구조는 다음과 같다. (핫스팟 oop관련 코드는 sun.jvm.hospot.oops 에서 찾아볼 수 있다)
- oop (추상 베이스)
- instanceOop (인스턴스 객체)
- methodOop (메서드 표현형)
- arrayOop (배열 추상 베이스)
- symbolOop (내부 심볼 / 스트링 클래스)
- KlassOop (Klass 헤더) (자바 7 이전만 해당)
- markOop
GC 루트 및 아레나
GC 루트는 메모리 풀 외부에서 내부를 가리키는 포인터이다. 메모리 풀 내부에서 같은 풀의 다른 메모리 위치를 가리키는 포인터를 내부 포인터(internal pointer), 반대인 것을 외부 포인터(external pointer)라고 한다. 핫스팟 GC는 아레나(arena)라는 메모리 영역에서 작동한다. 핫스팟은 자바 힙을 관리할 때 시스템 콜을 하지 않는다.
할당과 수명
자바 애플리케이션에서 가비지 수집이 일어나는 주된 원인은 다음과 같다
- 할당률
- 일정 기간 새로 생성된 객체가 사용한 메모리량
- 객체 수명
- 객체는 생성된 후 잠시 동안만 존재한다. 따라서 사용한 메모리를 회수해 사용한다.
약한 세대별 가설 (Weak Generation Hypothesis)
약한 세대별 가설은 JVM 메모리 관리의 이론적 근간을 형성한 지식이다.
1
2
JVM 및 유사 소프트웨어 시스템에서 객체 수명은 이원적 분포 양상을 보인다.
거의 대부분의 객체는 아주 짧은 시간만 살아 있지만, 나머지 객체는 기대 수명이 훨씬 길다.
결국 가비지를 수집하는 힙은 단명 객체를 쉽고 빠르게 수집하면서 장수 객체와 단명 객체를 분리해야 한다. 약한 세대별 가설은 다음과 같은 핫스팟 매커니즘에 사용되었다.
- 객체마다 세대 카운트(geneartion count - 객체가 지금까지 무사통과한 가비지 수집 횟수)를 센다
- 큰 객체를 제외한 나머지 객체는 에덴(Eden) 공간에 생성한다. 살아남은 객체는 다른 곳으로 옮긴다
- 장수한 객체들은 별도의 메모리 영역 (old 또는 tenured)에 보관한다
이렇게 메모리 영역을 나눌 때 영 세대 내부를 가리키는 포인터를 계속 추적한다. 그래야 GC에서 살아남은 객체들을 찾기 위해 그래프를 다 뒤질 필요가 없다. JVM은 늙은 객체가 젊은 객대를 참조하는지를 빠르게 알기 위해 카드 테이블 자료구조에 이 정보를 기록한다. 각 원소는 올드 세대 공간의 512바이트 영역을 가리킨다. 늙은 객체와 젊은 객체의 관계가 맺어지면 카드 테이블 엔트리를 더티 값으로 세팅하고, 해제되면 지운다.
핫스팟의 가비지 수집
프로세스가 시작되면 JVM 메모리를 할당하고 유저 공간에서 연속된 단일 메모리 풀을 관리한다. 이 메모리 풀은 목적에 따라 여러 영역으로 나뉘며 객체 생성은 에덴 영역에서 이루어진다. 또 한, 수집기가 시간 흐름에 따라 객체 위치를(주소를) 바꾼다. 이렇게 위치를 바꾸는 수집기를 방출 수집기라고 한다.
이 메모리 풀은 다음과 같은 구조로 나누어져 있다.
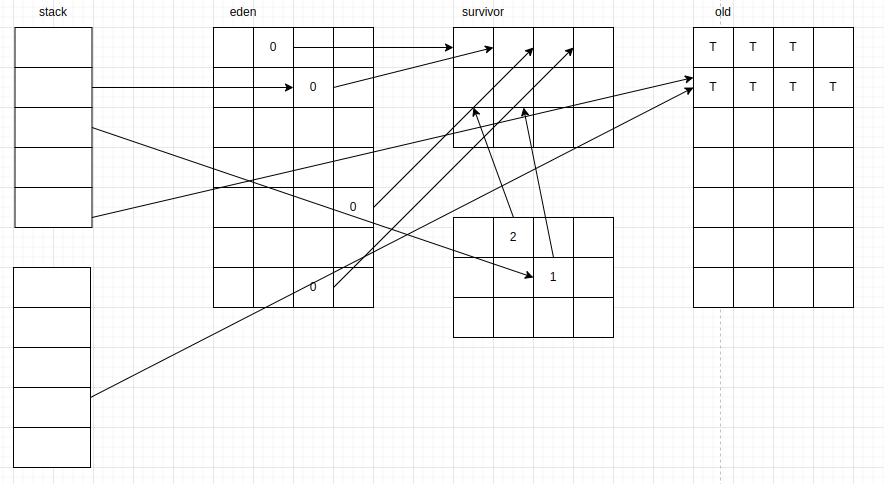
스레드 로컬 할당 (Thread-Local Allocation Buffer - TLAB)
에덴에서 탄생한 단명(다음 GC 사이클까지 못 버티는 객체) 객체는 다른 곳에 위치할 수 없어서 특별히 잘 관리해야 한다. JVM은 에덴을 여러 버퍼로 나누어 각 애플리케이션 스레드가 새 객체를 할당하는 구역으로 활용하게 배포한다. 스레드는 객체 생성 시 필요한 공간을 할당하고 스레드-로컬 포인터는 그다음으로 비어있는 메모리 주소를 가리키게 업데이트한다. 때문에 스레드 할당 복잡도는 O(1)이다. 다른 스레드는 자신 버퍼에 객체를 할당할 수 없다. 이 구역을 스레드 로컬 할당 버퍼라고 한다. 핫스팟은 TLAB 크기를 동적으로 조절한다. 따라서 메모리 소비가 큰 스레드가 있다면 더 큰 TLAB를 할당한다.
반구형 방출 수집기 (hemispheric evacuating collector)
두 공간을 사용하는 수집기이다. 위 그림에서 survivor에 해당한다. 반구형 방출 수집기는 보통 크기가 같은 두 공간을 사용하는 수집기이다. 장수하지 못하는 객체들을 담아두는 임시 수용소 역할을 해서 테뉴어드 세대를 어지럽히지 않고 풀 GC 발생 빈도를 줄인다. 이 두 공간(반구)은 다음과 같은 특성을 지닌다
- 수집기가 라이브 반구를 수집할 때 객체들은 다른 반구로 압착시켜 옮기고 수집된 반구는 비워서 재사용한다
- 절반의 공간은 항상 완전히 비운다
한 번에 한 공간만 사용하기 때문에 실제 보관 가능한 메모리 보다 2배 더 많은 용량을 사용한다는 단점이 있다. 핫스팟은 이 반구형 기법과 에덴 공간을 접목해 영 세대를 수집한다.
병렬 수집기(parallel collector)
자바 8 이전까지 JVM 디폴트 가지비 수집기는 병렬 수집기였다. 병렬 수집기는 처리율에 최적화되어 있고 영 GC, 풀 GC 모두 풀 STW를 발생시킨다. 애플리케이션 스레드를 모두 중단시키고 가용 CPU코어를 총동원해 가능한 빨리 메모리를 수집한다.
영 세대 병렬 수집
스레드가 에덴에 객체 할당을 시도할 때 자신이 할당받는 TLAB 공간은 부족하고 JVM은 새 공간을 할당할 수 없을 때 다음과 같은 과정을 거쳐 GC를 동작시킨다.
- 전체 애플리케이션 스레드를 중단시킨다.
- 영 세대(에덴, 현재 비어있지 않은 서바이버 공간)를 뒤져서 가비지가 아닌 객체를 골라낸다. 이때 GC 루트를 병렬 마킹 스캔 작업의 출발점으로 삼는다.
- 병렬 GC는 살아남은 객체를 비어있는 survivor 공간으로 방출한다.
- 방출한 객체의 세대 카운트를 늘린다
- 이제 막 방출시킨 survivo 공간과 에덴을 재사용 가능한 빈 공간으로 표시한다
- 애플리케이션 스레드를 재시작해 TLAB을 애플리케이션 스레드에 배포하는 프로세스를 재개한다
올드 세대 병렬 수집
Parallel old GC는 자바 8 기준 올드 세대 수집기이다. Parallel old GC는 하나의 연속된 메모리 공간에서 압착하는 수집기이고 parallel GC는 객체를 방출하는 반구형 수집기라는 점에서 차이가 존재한다. 올드 세개에 더 이상 방출할 공간이 없으면 병렬 수집기는 올드 세대 내부에서 객체들을 재배치하고 객체가 죽고 버려진 공간을 회수한다. 때문에 메모리를 효율적으로 사용하고 메모리 단편화가 일어날 일이 없다.
병렬 수집기의 한계
병렬 수집기는 세대 전체 콘텐츠를 대상으로 한 번에 가비지를 수집한다. 때문에 풀 STW를 유발한다는 단점이 존재한다. 영 세대의 경우 극소수 객체만 살아남기 때문에 STW가 큰 문제가 되지 않는다. 그러나 올스 세대는 사정이 다르다. 올드 세대 디폴트 크기는 영 세대에 비해 7배 크다. 또 한, 마킹 시간은 영역 내 살아있는 객체 수에 비례한다. 올드 객체는 풀 수집 시 상당수가 살아남을 가능성이 크다. 올드 수집의 가장 큰 약점은 STW 시간이 힙 크기에 거의 비례한다는 것이다.