데이터베이스는 통상적으로 한 레코드에 존재하는 모든 속성과 데이터를 하나의 레코드로 저장하고, 이 레코드들을 파일에 저장한다. 이러한 방식을 행 기반 저장소(row-oriented storage) 리고 한다. 이와 반대로 열 지향 저장소는 속성을 기준으로 그 속성에 해당하는 모든 연속된 값들을 함께 저장한다. 가장 간단한 열 지향 저장소는 속성 별로 서로 다른 파일에 저장한다. 또 한, 각 파일은 크기를 줄이기 위해 압축된다. 이러한 구조적 특성 때문에 테이블 i번째 행 전체에 접근할 경우 각 i번째 위치에 있는 값을 검색해 행을 재구성해야 한다. 즉, 단일 레코드의 여러 속성을 읽어오기 위해 여러 번의 I/O가 필요하는 단점이 존재한다. 그에 반해 많은 수의 튜플에 접근하되 일부 속성에 자주 접근한다면 열 지향 저장소가 더 유리하다. 그 이유는 다음과 같다.
- 감소한 I/O: 필요 없는 속성을 디스크에서 메모리로 읽어올 필요가 없기 때문에 I/O를 감소시켜 쿼리 실행 비용을 아낀다.
- 향상된 CPU 캐시 성능: 쿼리 처리기가 특정 속성 내용을 읽어 올 때, 최신 CPU 구조를 사용해 캐시 라인(cache line)이라고 하는 여러 연속된 바이트가 메모리에서 CPU 캐시로 읽힌다. 만약 이후에 캐시로 가져온 바이트를 사용한다면 메모리에서 가져오는 것보다 훨씬 더 빠르게 처리할 수 있다. 이 때, 행 지향 저장소는 필요하지 않은 속성값이 포함된 인접 바이트까지 캐시로 가져오기 때문에 캐시 공간과 메모리 대역폭이 낭비된다. 반대로 열 지향 저장소는 이런 문제가 발생하지 않는다.
- 개선된 압축: 같은 타입인 데이터를 한 번에 압축하는 것이 압축 효율성이 좋다. 대부분의 쿼리에서 디스크에 있는 데이터를 검색하는 데 가장 많은 비용이 든다. 압축은 이 검색 시간을 크게 줄여준다. 또 한, 압축된 파일이 메모리에 저장되면 사용하는 메모리 공간을 그만큼 줄일 수 있다.
- 벡터 처리(vector processing): 배열의 여러 요소에 CPU 연산을 병렬로 실행할 수 있는 것을 말한다. 열 단위로 데이터를 저장하면 속성과 상수를 비교하는 것과 같은 연산을 벡터 처리할 수 있게 된다. 이는 테이블의 선택 조건을 적용하는 데 중요하다. 또 한, 벡터 처리는 한 번에 하나씩 값을 집계하는 대신 병렬로 여러 값의 집계를 계산하는 데 사용되기도 한다.
열 지향 저장소에 사용되는 DB는 열 저장소(column store)라고 불리고, 행 지향 저장소에 사용되는 DB는 행 저장소(row store)라고 불린다. 열 지향 저장소는 다음과 같은 단점으로 인해 트랜잭션 처리에 적합하지 않다.
- 튜플 재구성 비용: 트랜잭션 처리 응용 프로그램에서는 레코드 재구성이 빈번히 발생한다. 그러나 위에서 설명했듯 열 지향 저장소에서 튜플 재구성은 많은 I/O가 필요하다.
- 튜플 삭제 및 갱신 비용: 압축된 형식에서 단일 레코드를 삭제 또는 갱신하려면 하나의 단위로 압축된 레코드 전체를 다시 써야 한다. 트랜잭션 처리 응용 프로그램에선 삭제와 갱신이 흔하기 때문에, 이 상황에서 열 지향 저장소를 사용하면 큰 비용이 발생한다. 따라서 열 지향 저장소를 사용하는 경우 작은 단위의 삭제와 갱신을 발생시키는 대산 새로운 레코드 삽입과 대량의 레코드 삭제만 지원하기도 한다.
- 압축 해제: 압축한 형식에서 데이터를 읽어오려면 우선 압축을 해제해야 한다. 트랜잭션 처리 쿼리는 통상적으로 몇 개의 레코드만 읽어와 사용한다. 열 지향 저장소를 사용한다면 몇 개의 레코드를 위해 관련 없는 많은 레코드의 압축을 해제해야 한다.
데이터 분석 질의는 많은 연속 레코드를 접근하기 때문에 압축 해제에 소요되는 시간이 크지 않다. 그럼에도 디스크 I/O를 줄이기 위해 불필요한 레코드를 건너뛸 필요가 있다. 이를 위해 열 지향 저장소는 압축 형식을 사용해 파일 이전 부분을 건너뛰고 임의 지점에서 압축 해제를 시작할 수 있다. 예컨대, 10,000개의 값마다 새로운 압축을 한다면 10,000개 단위로 레코드를 건너 뛰면서 압축을 해제해 좀 더 빠르게 원하는 값에 접근할 수 있다.
일부 열 기반 저장소 시스템은 각 열을 다른 파일로 나눠서 저장하는 대신, 자주 접근하는 열 그룹을 한곳에 같이 저장할 수 있다. 때문에 이 시스템은 모든 열을 별도로 저장하는 것부터 모든 열을 한곳에 저장하는 행 지향 저장소까지 다양한 선택 폭을 제공한다.
SAP HANA와 같은 일부 DB는 두 개의 하부 저장 장치 시스템을 지원한다. 하나는 트랜잭션 처리를 위한 행 지향 저장소이고, 다른 하나는 데이터 분석을 위한 열 지향 저장소다. 통상적으로 행 지향 저장소에 레코드를 생성하고 더 이상 행 지향 방식으로 접근하지 않는다면 해당 레코드를 열 지향 저장소로 이주시킨다. 이런 시스템은 하이브리드 행/열 저장소(hybrid row/colun store)라고 한다.
메인 메모리에서 열 지향 저장소를 사용한다면, 열의 모든 값을 연속적인 메모리 위치에 저장할 수 있다. 하지만, 데이터를 새로 추가한다면 연속적인 할당 보장을 위해 기존 데이터를 재할당해야 한다. 이 오버헤드를 줄이기 위해 간접 테이블(indiretion table)을 사용한다. 이는 논리적 배열을 여러 물리적 배열로 나누고 간접 테이블에 물리적 배열에 대한 포인터를 저장하는 방식이다.
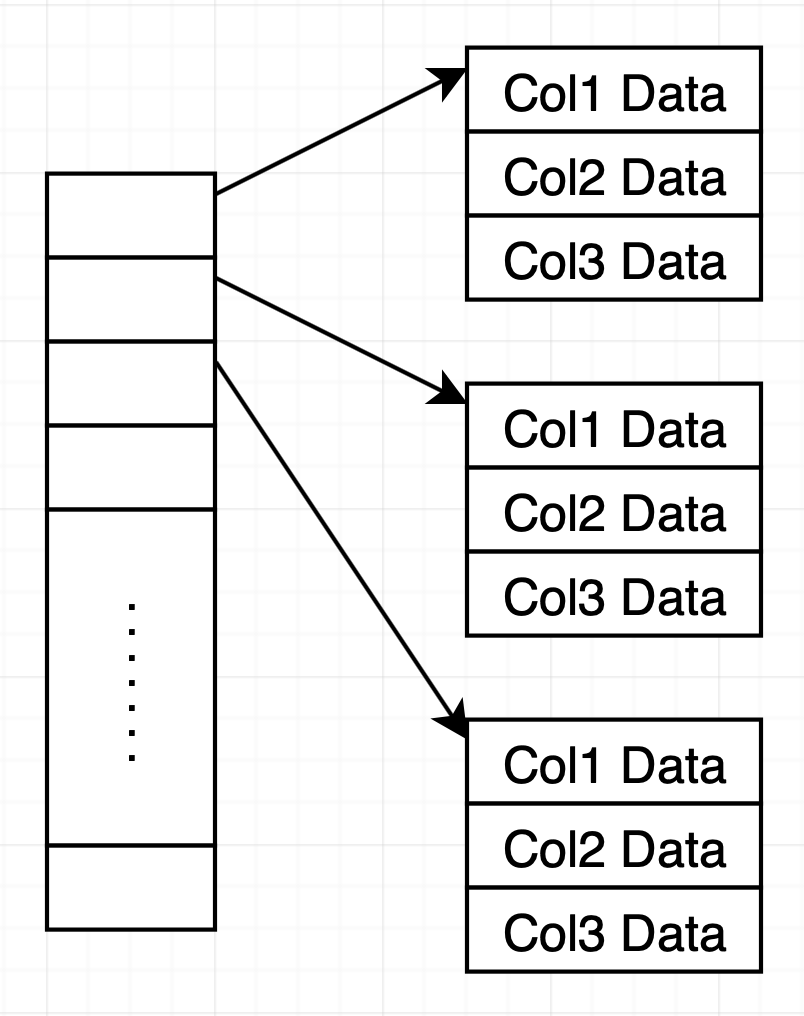 이 구조에서 i번째 요소를 찾는다면 간접 테이블을 통해 i번째 요소를 포함하는 물리적 배열을 찾고, 오프셋을 계산해 해당 물리 배열에서 요소를 조회한다.
이 구조에서 i번째 요소를 찾는다면 간접 테이블을 통해 i번째 요소를 포함하는 물리적 배열을 찾고, 오프셋을 계산해 해당 물리 배열에서 요소를 조회한다.