값이 싸고 크기가 작은 컴퓨터를 네트워크로 묶어 대형 컴퓨터 같은 능력을 가진 시스템을 만드는 것을 분산 시스템이라 한다. 분산 시스템 내의 컴퓨터는 각자 작업을 처리하고 그 내용이나 결과를 서로 공유한다. 분산 시스템 장점은 다음과 같다.
- 네트워크로 연결된 기기가 여러 자원을 공유할 수 있다.
- load balancing을 통해 여러 기기가 작업을 나누어 처리할 수 있다.
- 데이터나 처리를 분산함으로써 연산 속도를 향상할 수 있다.
- 장애가 발생해도 시스템을 복구할 수 있다.
분산 시스템은 각 기기의 독립성을 보장하고, 사용자는 시스템을 하나의 기기로 인식할 수 있어야 한다. 이를 위해 분산 시스템은 네트워크를 구성하는 각 기기의 자율성(autonomy)을 보장하고, 자원 분산과 중복을 통한 가용성(availability)을 높이고, 특정 자원에 대한 위치 투명성(transparency)을 보장해야 한다. 분산 시스템에 사용되는 운영체제는 크게 두 가지로 나뉜다.
- 네트워크 운영체제(NOS - Network Operating System) 각 컴퓨터가 독자적인(서로 다를 수도 있다) OS를 가지고 사용자 프로그램을 통해 분산 시스템이 구현된다. 지역적으로 널리 분산된 대규모 네트워크에서 사용하고 기기의 OS가 다르기 때문에 사용자 기기와 OS 종류와 사용법을 모두 알고 있어야 한다. 기능적으로 제약이 많다.
- 분산 운영체제(DOS - Distributed Operating System) 전체 네트워크가 단일 운영체제로 운영된다. 사용자가 시스템 내 기기 종류를 알 필요가 없고, 전체 시스템을 일관성 있게 설계할 수 있다. 네트워크 유지 보수가 용이하다.
Distributed File System(DFS)
클라이언트/서버 시스템
완전한 분산 시스템은 각 컴퓨터가 독립적으로 작동하기 때문에 한 컴퓨터가 비정상 종료되면 중단된 작업을 다른 컴퓨터로 옮기거나 결과를 합치는 등 여러 문제가 존재했다. 이 문제를 해결하기 위해 나온 것이 클라이언트/서버 시스템이다. 클라이언트/서버 시스템은 작업을 요청하는 클라이언트와 요청받는 작업을 처리하는 서버의 이중 구조로 되어있다.
 여기서 서버를 데몬이라고 표시했는데, 멈추지 않고 계속 작동하는 프로그램을 데몬이라 한다. 웹 시스템에서 사용하는 데몬을 HTTP 데몬, 또는 웹 데몬이라 한다. 아파치 톰캣이 웹 데몬의 한 예시이다.
클라이언트/서버 시스템은 SPoF(Single Point of Failure) 문제를 겪을 수 있다. 이를 방지하기 위해 중복된 컴포넌트들을 사용하고 장애 감지와 복구 프로세스를 통해 서버 연산을 지속할 수 있다.
여기서 서버를 데몬이라고 표시했는데, 멈추지 않고 계속 작동하는 프로그램을 데몬이라 한다. 웹 시스템에서 사용하는 데몬을 HTTP 데몬, 또는 웹 데몬이라 한다. 아파치 톰캣이 웹 데몬의 한 예시이다.
클라이언트/서버 시스템은 SPoF(Single Point of Failure) 문제를 겪을 수 있다. 이를 방지하기 위해 중복된 컴포넌트들을 사용하고 장애 감지와 복구 프로세스를 통해 서버 연산을 지속할 수 있다.
CGI와 미들웨어
동적인 데이터를 HTML에 삽입할 필요성이 증가하면서 이 작업을 하기 위해 프로세스에 질문을 하고 그 결괏값을 HTML 형태로 웹 데몬에 전달하는 프로세스가 필요했다. 이를 위해 개발된 것이 CGI(Common Gateway Interface)이다. 초기 CGI는 간단한 작업만 가능했지만 게임, 교육 등 작업을 웹에서 하게 되면서 DB와 웹 서버 연결 작업에 CGI를 사용하기 시작했다. 웹 데몬용 소프트웨어를 만드는 회사들은 CGI를 프로그래밍 언어 형태로 만들어 개발자에게 제공했는데, 그 예시가 PHP이다. 미들웨어는 양쪽을 연결해 통신할 수 있게 중간에서 매개 역할을 하는 소프트웨어다. 필요에 따라 서버나 DB를 증설할 때, 증설한 기종이 서로 다르다면 미들웨어로 서로 다른 기종들을 묶어서 표준화된 인터페이스를 통해 일관된 작업을 할 수 있다. 운영체제와 애플리케이션 중간에 존재하는 가상머신이 미들웨어의 한 종류다.
P2P 시스템
클라이언트/서버 시스템의 가장 큰 문제는 서버 과부하이다. 많은 요청이 서버로 몰리면 웹 서비스 제공자는 많은 서버와 큰 용량의 네트워크를 사용해야 한다. 또 한, 서버에 모든 서비스가 집중되기 때문에 서버 고장 시 서비스가 중단될 수 있다. 이 문제를 해결하기 위해 분산 시스템을 기본으로 하면서 서버의 부하를 줄이고 몇 개의 컴퓨터가 고장 나도 서비스를 유지할 수 있는 시스템이 설계되었다. 이것이 P2P 시스템이다. P2P 시스템은 다음과 같은 종류로 나뉜다.
- 비구조적 시스템:
- 서버가 전체 노드에 대한 정보를 가지고 있다.
- 전체 네트워크에 대한 정보를 모든 노드에 저장하거나 하나의 노드에 집중 저장해 관리한다.
- 실제 데이터 전송만 일대일로 연결된 말단 노드를 통해 이루어진다.
- 데이터 송신 측이 프로그램을 중단하면 수신 측은 더 이상 데이터를 받지 못한다.
- 서버가 전체 노드에 대한 정보를 가지고 있다.
- 구조적 시스템:
- 각 노드가 부분적인 네트워크 정보를 유지해 비구조적 시스템의 단점을 보완했다. 특정 파일의 소유자 정보를 여러 노드가 공유해서, 시스템의 한 노드가 사라져도 데이터 공유가 지속적으로 이루어진다.
클라우드 컴퓨팅
그리드 컴퓨팅(grid computing)은 이기종(heterogeneous) 컴퓨터들을 묶어 대용량 컴퓨터 풀을 구성하고 이를 원격지로 연결해 대용량 연산을 수행하는 컴퓨팅 환경이다. 하드웨어적으로 컴퓨팅 환경을 통합한 방식이다. 그리드 컴퓨팅은 데이터 연산을 소규모 연산으로 나누어 여러 대의 컴퓨터에 분산해 수행한다. 그리드는 다음과 같이 세 가지로 나뉜다.
- 계산 그리드: 날씨 계산같이 많은 양의 연산이 필요한 컴퓨팅 환경에서 사용한다.
- 데이터 그리드: 대용량 데이터를 처리하기 위해 고안된 그리드
- 액세스 그리드: 다수의 사용자가 협업할 수 있게 고안된 그리드
기존 저장 장치와 서버를 그리드로 묶어 사용하려면 미들웨어가 필요하다. 미들웨어는 이기종 컴퓨터들을 묶어 그리스 서비스를 제공해서 사용자가 일관된 서비스를 받을 수 있게 한다. 그리드와 달리 소프트웨어적으로 컴퓨팅 환경을 통합한 방식도 존재한다.
- SaaS(Software as a Service): 사용자가 필요한 소프트웨어 기능만 필요할 때 이용하고, 이용한 기능만큼만 비용을 지불하는 개념. 네트워크를 통해 표준화된 솔루션을 서비스한다.
- IaaS(Infrastrcuture as a Service): 서버 소프트웨어 데이터 공간 같은 컴퓨터 하부 구조를 서비스하는 가상화 구조
- PaaS(Platform as a Service): 개발 환경을 서비스하는 것
고가용성(High Availability)
고가용성은 서비스 중단을 최소화하기 위해 이중화 작업을 하는 것이다. 고가용성 보장을 위해선 2대 이상의 시스템을 하나의 클러스터로 묶고, 시스템 장애 발생 시 클러스터 내의 다른 시스템으로 서비스를 이동할 수 있게 해야 한다.
고가용성 구성 유형
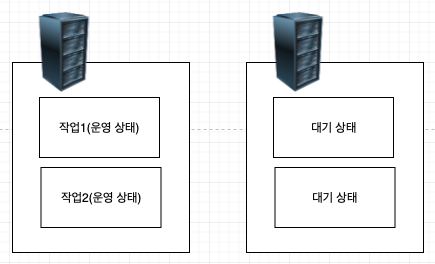
상시 대기(hot-standby)
가장 단순하면서 많이 사용되는 방식이다. 가동 시스템과 백업 시스템으로 구성된다. 백업 시스템은 평상시 대기 상태를 유지하다가 가동 시스템에 장애가 발생하면 자원을 백업 시스템으로 이전해 서비스가 중단되지 않게 한다. 외부 저장 장치는 오직 현재 가동 중인 시스템에서만 접근이 가능해서 데이터 일관성이 보장된다.
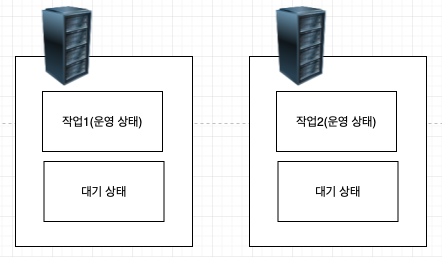
상호 인계(multual takeover)
2개의 시스템이 각각의 고유 작업을 수행하다가 한쪽 시스템에서 장애가 발생하면 해당 시스템이 수행 중이던 작업을 이동시켜 동시에 2개의 작업을 서비스한다. 각 시스템은 장애 발생에 대비해 2개의 작업을 동시에 서비스할 수 있는 시스템 용량을 갖추고 있다. 외부 저장 장치는 작업이 이루어지는 시스템에서만 접근할 수 있어서 데이터의 일관성이 보장된다.
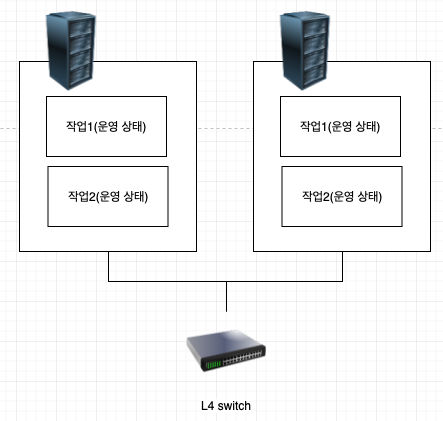
concurrent access
여러 시스템이 동시에 업무를 나누어 병렬 처리한다. 시스템 전체가 가동 상태로 업무를 수행하기 때문에 한 시스템에 장애가 발생해도 다른 시스템으로 작업을 이동하지 않고도 고가용성을 유지할 수 있다. 여러 시스템에게 작업을 분배하기 위해 L4 스위치를 이용한다. 외부 저장 장치는 전체 시스템에서 접근 가능하다.
시스템 복구 절차
위에서 고가용성 구성 유형을 시스템 장애 발생 시 복구 방식에 따라 설명하였다. 이제 어떻게 장애 발생을 판단하고 재설정을 거친 뒤 시스템을 복구시킬 수 있는지를 살펴보자. 아래 글에서 시스템은 분산 시스템 자체를 의미하며 사이트는 노드나 서버를 나타낸다.
장애 감지
공유 메모리가 없는 환경에선 장애가 발생하면 장애 발생 원인을 정확히 파악하기 어렵다. 추가적인 조치가 없다면 그저 연결 장애(link failure), site failure, host failure, message loss 중 하나라고 추측만 할 수 있다. Link failure 또는 site failure 장애 발생을 판단하기 위해선 heartbeat procedure를 사용하면 된다. heartbeat procedure는 주기적으로 cluster 내에 있는 다른 서버들에게 자신이 정상 상태라는 메시지를 보내는 방법이다(heartbeat에 대해 더 자세한 설명이 궁금하다면 링크를 참고하자.). A 서버와 B 서버가 서로 heartbeat를 주고받는다고 해보자. 이 떄, A가 B의 heartbeat message를 받지 못했다면 A는 B 서버 측에 장애가 발생했음을 알 수 있다. 이 때, A는 다음과 같은 두 가지 조치를 취할 수 있다.
- 메시지가 중간에 loss된 것일 수도 있으므로 한 번 더 기다린다
- B 서버의 health check를 할 수 있는 메시지를 보낸다
만약 위와 같은 조치를 취했음에도 추가적인 hearbeat message를 받지 못했다면 같은 절차를 한 번 더 실행해 볼 수 있다. 그럼에도 같은 상황이라면 link failure 또는 site failure이 발생했다는 결론을 내릴 수 있다. 이 상황에서 만약 health check를 할 수 있는 다른 방식이 존재한다면 장애 발생 원인이 정확히 link failuer과 site failure 중 어느 것인지 판단할 수 있다. 다른 경로로 health check message를 보냈을 때 응답이 A의 time-out 시간 내에 정상적으로 돌아왔다면 이는 link failure이다. 만약 응답을 time-out 시간 내에 받지 못했다면 다음과 같은 상황이 발생했음을 추측할 수 있다.
- Site B가 다운되었다
- 만약 A가 B와 통신할 수 있는 방식이 오직 하나라면 A와 B를 연결하는 link에 문제가 발생했다
- 시도했던 또 다른 방식을 거치는 link 역시 다운되었다
- 메시지가 전송 도중 loss되었다.
장애 발생에 따른 조치
위와 같은 방식으로 장애 발생을 감지했을 때, 장애가 발생한 서버와 통신하는 정상적인 서버는 다음과 같은 조치를 취해야 한다.
- 만약 두 서버를 직접적으로 연결하는 물리적인 링크가 존재하고, 이 링크에 문제가 발생했다면 시스템에 존재하는 나머지 사이트들에게 이 사실을 broadcast 해서 장애가 발생했음을 알려야 한다. 이를 통해 라우팅 테이블이 라우팅에 관한 정보를 업데이트해야 한다.
- 만약 시스템이 사이트에 접근할 수 없어서 해당 사이트에 장애가 발생했다고 판단한다면, 시스템 내에 있는 다른 사이트들에게 이를 알려서 더 이상 장애가 발생한 사이트를 사용하지 않게 해야 한다.
장애 복구 완료 후
장애가 복구된 후에는 다음과 같은 방법으로 시스템에 매끄럽게 통합되어야 한다.
- 만약 link 장애로 인한 문제가 해결되었다면 연결된 모든 서버에게 복구 완료를 알려야 한다. 이는 서로에게 보내는 heartbeat message가 정상적으로 도착하는 것을 통해 알 수 있다.
- 장애가 발생한 사이트가 복구되었다면 다른 모든 사이트들에게 복구되었음을 알려야 한다. 이때, 복구된 서버는 자신과 연결된 DB에 업데이트해야 할 정보를 담은 요청들을 다른 사이트로부터 받을 수 있다.