파일 구성
데이터 베이스는 기본적으로 운영체제가 관리하는 여러 파일로서 존재하게 된다. 이 파일들은 디스크에 저장된다. 파일은 일련의 레코드로서 논리적으로 구성된다. 하나의 파일은 블록이라는 고정길이 저장 단위로 논리적으로 분할된다. 각 블록의 기본 크기는 4KB ~ 8KB이다. 하나의 블록은 다시 여러 개의 레코드를 저장한다. 단일 블록은 각 레코드를 완전히 포함한다. 이를 통해 데이터 항목에 접근하는 것을 단순화하고 접근 속도를 향상한다. 종합적으로 다음과 같은 관계를 갖는다(‘-‘왼쪽 요소는 오른쪽 요소로 구성된다).
1
disk - file - block - record
고정길이 레코드
레코드 하나의 길이는 고정일 수도 있고 가변일 수도 있다. 우선 고정길이 레코드에 대해 살펴보자. 고정길이 레코드를 사용하면 다음과 같은 문제가 존재한다. 각 레코드 길이를 n이라 하자.
- 만약 블록 크기가 n의 배수가 아니라면, 일부 레코드들은 블록 경계를 넘는다. 따라서 해당 블록 접근 시에 두 블록에 모두 접근해야 한다.
- 레코드를 삭제하기 어렵다. 삭제할 레코드가 차지하는 공간은 그 파일의 다른 레코드로 채워야 한다. 아니면 그 공간을 무시할 수 있게 레코드를 삭제했다는 표시를 해야 한다.
첫 번째 문제를 해결하기 위해선 온전한 크기의 레코드를 채울 수 있는 만큼만 채우고, 나머지 공간은 무시하면 된다. 두 번째 문제 해결 방법은 조금 복잡하다. 삭제할 레코드가 차지하는 공간을 파일의 다른 레코드로 채우는 경우 빈 곳을 채우기 위한 부차적인 레코드 접근이 필요해 비용이 많이 발생한다. 따라서 레코드 삽입이 레코드 삭제보다 더 자주 일어난다는 특성을 이용해 레코드 삭제로 인해 비워진 공간을 재사용하기 전 다음에 삽입할 레코드를 기다리게 할 수 있다. 삭제한 레코드 공간을 단순히 표시만 한다면 레코드 삽일 시 이용 가능한 공간을 찾기 어렵다. 따라서 다음과 같은 방법을 사용하면 된다.
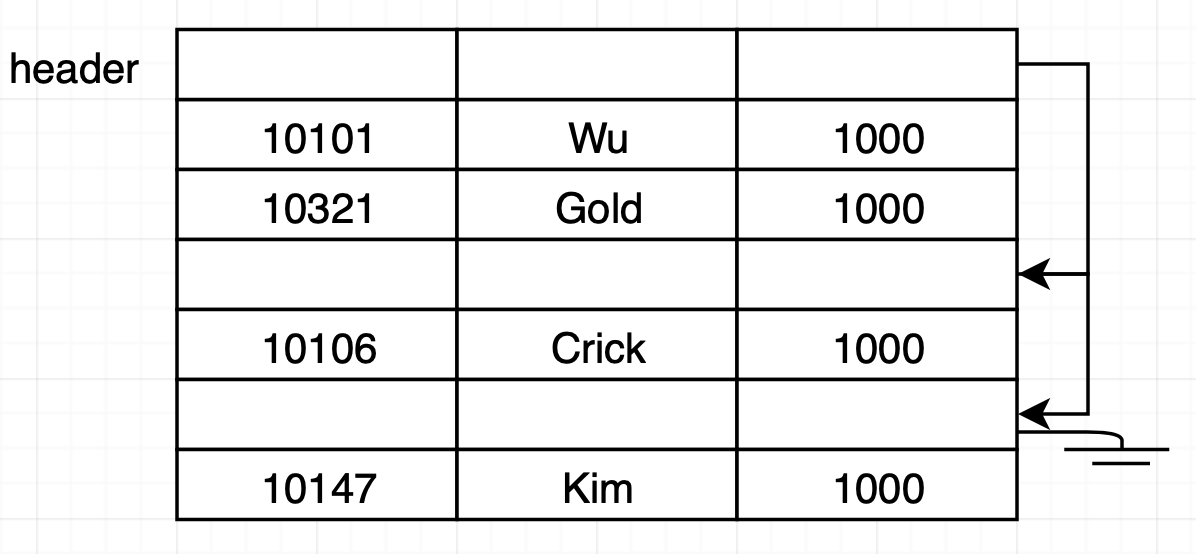
- 파일 맨 앞부분에 파일 헤더를 만든다. 파일 헤더에는 파일에 대한 정보와 내용이 삭제된 첫 번째 레코드 주소가 존재한다.
- 내용이 삭제된 n 번째 레코드 주소는 내용이 삭제된 n+1 번째 레코드 주소를 가진다. 이렇게 리스트 형태를 가진다.
- 새로운 레코드를 삽입할 때 헤더가 가리키는 레코드를 사용한다. 없다면 파일 끝에 레코드를 삽입한다.
가변길이 레코드(variable-length record)
고정길이 레코드는 레코드 길이기 일정해 삽입, 삭제에 용이하다. 하지만 가변길이 레코드에서는 비워진 공간이 삽입할 레코드와 맞지 않는 등의 문제가 존재한다. 가변길이 레코드는 문자열 같은 가변 길이 필드, 배열이나 다중 집합(multiset)과 같은 반복적인 필드를 포함하는 레코드 유형과 파일 내에 여러 레코드 유형 존재로 인해 필요하다. 가변길이 레코드를 올바르게 구현하기 위해선 다음과 같은 두 가지 문제를 해결해야 한다.
- 속성이 가변 길이인 경우에도 개별 속성을 쉽게 추출할 수 있는 방식으로 하나의 레코드를 표현하는 방법
- 블록 내의 레코드를 쉽게 추출할 수 있게 블록 내에 가변 길이 레코드를 저장하는 방법
개별 속성을 레코드에서 쉽게 추출하는 방법부터 알아보자. 가변 길이 속성을 지닌 레코드는 통상적으로 두 부분으로 구성된다.
- 고정 길이 정보를 갖는 부분
- 해당 정보를 저장하는 데 필요한 바이트 수만큼을 할당해 사용한다.
- 가변 길이 속성의 내용으로 구성된 부분
- 레코드 처음 부분에 [offset, length] 쌍으로 가변 길이 속성을 표현한다.
- offset은 레코드 내에 속성이 시작되는 부분을 나타낸다
- length는 가변 길이 속서의 바이트 길이이다.
- 레코드 처음 부분에 [offset, length] 쌍으로 가변 길이 속성을 표현한다.
이 구조에 대한 예시는 다음과 같다.
 저장된 방식에 따라 10101, Srinivasan, Comp. Sci는 모두 가변길이 속성이고 65000은 고정길이인 것을 알 수 있다.
여기서 null bitmap은 어떤 레코드 속성이 null 인지를 나타낸다. 해당 레코드는 총 4 개의 컬럼이 존재하므로 null bitmap은 4bit이다. null bitmap의 n 번째 비트가 1이면 n 번째 속성은 null이다.
저장된 방식에 따라 10101, Srinivasan, Comp. Sci는 모두 가변길이 속성이고 65000은 고정길이인 것을 알 수 있다.
여기서 null bitmap은 어떤 레코드 속성이 null 인지를 나타낸다. 해당 레코드는 총 4 개의 컬럼이 존재하므로 null bitmap은 4bit이다. null bitmap의 n 번째 비트가 1이면 n 번째 속성은 null이다.
블록 내에서 쉽게 가변길이 레코드를 저장하기 위해 slotted-page structure를 사용한다. 각 블록 시작 점에는 다음과 같은 정보를 가지는 헤더가 존재한다.
- 헤더에 있는 레코드 엔트리 수
- 블록에서 빈 곳의 끝
- 각 레코드의 위치와 크기를 포함하고 있는 엔트리 배열
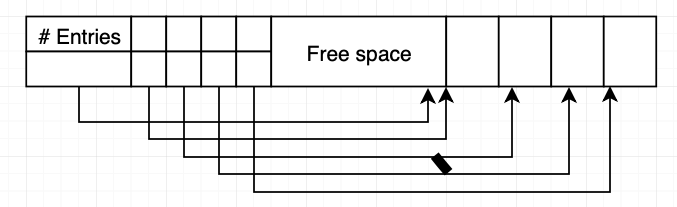
레코드들은 블록 끝에서부터 인접하게 할당된다. 레코드 하나가 삽입되면 레코드를 위한 공간을 빈 공간 끝에서부터 할당하고 레코드 크기와 위치를 포함하는 엔트리를 헤더에 추가한다. 레코드를 삭제하면 레코드가 차지하던 공간을 지우고 이에 대응되는 엔트리는 삭제한 상태로 표기한다. 그 후 삭제한 레코드 앞에 있는 레코드들을 이동시키고 빈 공간 끝을 가리키는 포인터를 갱신한다. slotted page structure를 사용할 때, 어떠한 포인터도 레코드를 직접 가리켜선 안된다. 대신 포인터는 레코드의 실제 위치를 포함하고 있는 헤더 안에 있는 엔트리를 가리키도록 해야 한다. 그래야 블록 공간 단편화를 막기 위한 레코드 이동이 가능하다.
대형 객체 저장 방법
대부분의 관계형 데이터베이스는 내부적으로 하나의 레코드 크기가 한 블록의 크기를 넘지 않게 제한한다. 그러나 데이터베이스에 대형 객체를 저장하는 경우도 존재한다. SQL은 이를 위해 blob(이진 대형 객체)와 clob(문자 대형 객체)를 지원한다. 대형 객체를 저장하는 방법은 다른 소형 속성과 다르다. 대형 객체를 별도로 저장한 뒤, 대형 객체에 대한 논리 포인터를 해당 객체를 포함하는 레코드에 저장한다. 대형 객체를 저장하는 방식은 두 가지로 나뉜다
- 데이터베이스가 관리하는 파일 시스템 영역에 파일로 저장한다
- 데이터베이스가 저장하고 관리하는 파일 구성으로 저장한다. (B+-tree 등) 대형 객체를 데이터베이스에 저장하는 행위는 성능 이슈가 존재한다.
- 과연 대형 객체를 데이터베이스 인터페이스를 통해 접근하는 것이 효율적인가
- 데이터베이스 백업 시 백업 용량이 커진다.
파일에 레코드를 구성하는 방법
지금까지 파일에 레코드 하나를 어떻게 저장할지를 설명했다. 이제 파일 안에서 레코드들을 어떻게 구성할 것인가를 알아보겠다.
힙 파일 구성(Heap file organization)
레코드는 릴레이션에 해당하는 파일 어디에나 저장할 수 있다. 레코드를 삽입할 때는 레코드 삭제로 인해 만들어진 빈 공간을 사용하는것이 좋다. 이 방법을 효율적으로 사용하기 위해서 레코드를 저장할 여유 공간이 있는 블록을 추적하는 자료구조를 사용한다. 이를 여유 공간 맵(free-space map)이라 한다. 여유 공간 맵은 각 블록에 대해 한 개의 엔트리를 포함하는 배열로 여유 공간 맵을 나타낸다.
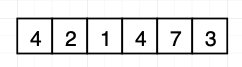 데이터베이스는 데이터 삽입 시 여유 공간 맵을 우선 탐색해 여유 공간이 있는 블록을 찾는다. 만약 없다면 새로운 블록을 추가한다.
만약 대용량 파일을 쓴다면 여유 공간 맵으로도 여전히 느리다. 이 경우 속도를 높이기 위해 2계층 여유 공간 맵을 만들 수 있다. 기존 여유 공간 맵 100개 엔트리 마다 한 개의 엔트리가 존재한다. 이 엔트리 한 개는 100개 엔트리 중 최댓값을 저장한다.
자유 공간 맵은 디스크에 존재하기 때문에 속도가 느려서 매번 맵의 엔트리를 갱신하지 못한다. 이 때문에 디스크의 여유 공간 맵은 최신 상태가 아닐 수도 있다. 이로 인해 발생할 수 있는 문제와 방지 대책은 다음과 같다.
데이터베이스는 데이터 삽입 시 여유 공간 맵을 우선 탐색해 여유 공간이 있는 블록을 찾는다. 만약 없다면 새로운 블록을 추가한다.
만약 대용량 파일을 쓴다면 여유 공간 맵으로도 여전히 느리다. 이 경우 속도를 높이기 위해 2계층 여유 공간 맵을 만들 수 있다. 기존 여유 공간 맵 100개 엔트리 마다 한 개의 엔트리가 존재한다. 이 엔트리 한 개는 100개 엔트리 중 최댓값을 저장한다.
자유 공간 맵은 디스크에 존재하기 때문에 속도가 느려서 매번 맵의 엔트리를 갱신하지 못한다. 이 때문에 디스크의 여유 공간 맵은 최신 상태가 아닐 수도 있다. 이로 인해 발생할 수 있는 문제와 방지 대책은 다음과 같다.
- 여유 공간이 없어도 여유 공간이 있다고 판단한다
- 실제 블록을 가져올 때 오류가 감지된다. 다른 블록을 찾기 위해 추가 검색을 한다.
- 여유가 있어도 없다고 판단한다.
- 사용하지 않는 여유 공간 외에는 문제가 되지 않는다.
순차 파일 구성(sequential file)
레코드의 효율적인 처리를 위해 검색 키를 기반으로 정렬한 순서대로 저장한다. 검색 키(search key)는 특정 속성들의 집합이며 반드시 super key나 primary key 일 필요는 없다. 각 레코드는 다음 레코드를 검색키 순서로 포인터를 이용해 연결한다. 또 한, 블록 접근을 최대한 줄이기 위해 레코드를 검색키 순서나 검색키 순서에 가깝게 저장한다.
 레코드를 삭제해도 물리적 순서를 유지하는 것은 많은 레코드 이동으로 인해 비용이 많이 든다. 따라서 삽입 시 다음과 같은 규칙을 적용해 삭제로 인한 비용을 줄일 수 있다.
레코드를 삭제해도 물리적 순서를 유지하는 것은 많은 레코드 이동으로 인해 비용이 많이 든다. 따라서 삽입 시 다음과 같은 규칙을 적용해 삭제로 인한 비용을 줄일 수 있다.
- 검색 키 순서로 볼 때 삽입할 레코드 바로 앞에 있는 레코드를 찾는다.
- 찾은 레코드와 같은 블록 내에 빈 레코드가 있다면 거기에 새로운 레코드를 삽입한다. 없다면 overflow block에 새로운 레코드를 삽입한다.
- overflow block은 데이터 삽입을 위해 기존 블록 밖에 새로 할당한 블록을 의미한다.
이 방식은 시간이 지날수록 물리적 순서와 검색 키 순서 간의 불일치가 커져서 순차 처리 효율이 떨어지는 문제가 있다. 따라서 재구성(reorganized)을 통해 순차적인 순서를 유지해 줘야 한다. 이는 비용이 많이 드는 작업이므로 시스템 작업량이 낮을 때 실행해야 한다.

다중 테이블 군집 파일 구성(multitable clustering file organization)
많은 관계형 데이터베이스는 각 릴레이션을 독립된 파일에 저장한다. 그 때문에 하나의 블록에는 하나의 릴레이션 코드만 존재한다. 이 경우 다음과 같은 연산이 발생한다면, 최악의 경우 각 레코드가 서로 다른 블록에 존재해서 레코드 하나에 블록을 한번 읽어야 할 수 있다. 예시는 다음과 같다.

1
2
select dept_name, building, budget, ID, name, salary
from department natural join instructor;
이 경우 단일 블록에 여러 릴레이션의 레코드를 저장하는 것이 효율적이다. 위 sql의 경우 dept_name에 대한 모든 instructor 레코드들을 해당 dept_name에 대한 department 레코드 가까이에 저장하면 된다. 바꿔 말하면 두 테이블은 dept_name 키에 대해 군집한다. department, instructor table의 다중 테이블 군집 파일 예시는 다음과 같다.
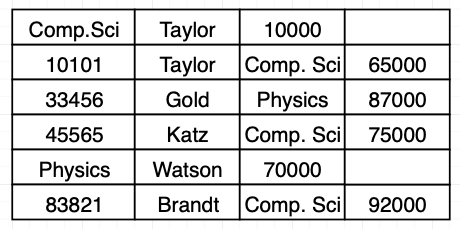 department 테이블 레코드 읽으면 읽어야 하는 레코드가 저장된 블록 전체가 메인 메모리로 복사된다. 이때 다중 테이블 군집 파일을 이용한다면 읽은 레코드에 대응되는 instructor 레코드도 같은 블록에 존재하므로 join을 효율적으로 처리할 수 있다. 만약 instructor 레코드 총 크기가 블록 하나 크기를 넘을지라도 근처에 있는 다른 블록을 사용한다.
다중 테이블 군집 파일 구성에서 군집키(cluster key)는 함께 저장되는 레코드를 정의하는 속성이다.
다중 테이블 군집 파일 구성은 조인에 대해선 속도가 빠르지만, 블록 하나 당 한 테이블에 존재하는 레코드를 더 적게 저장하므로 다른 질의문 처리 속도는 느려진다.
department 테이블 레코드 읽으면 읽어야 하는 레코드가 저장된 블록 전체가 메인 메모리로 복사된다. 이때 다중 테이블 군집 파일을 이용한다면 읽은 레코드에 대응되는 instructor 레코드도 같은 블록에 존재하므로 join을 효율적으로 처리할 수 있다. 만약 instructor 레코드 총 크기가 블록 하나 크기를 넘을지라도 근처에 있는 다른 블록을 사용한다.
다중 테이블 군집 파일 구성에서 군집키(cluster key)는 함께 저장되는 레코드를 정의하는 속성이다.
다중 테이블 군집 파일 구성은 조인에 대해선 속도가 빠르지만, 블록 하나 당 한 테이블에 존재하는 레코드를 더 적게 저장하므로 다른 질의문 처리 속도는 느려진다.
분할(table partitioning)
테이블의 레코드를 더 작은 테이블로 분할해 따로 저장할 수 있다. 이를 테이블 분할(table partitioning)이라 한다. 테이블 분할은 보통 속성 값을 기준으로 실행된다. 예를 들어 회계 관련 테이블인 transaction을 year를 기준으로 transaction_2018, tarnsaction_2019로 나누는 식이다. 레코드 여유 공간을 찾는 등 일부 연산 비용은 테이블 크기에 비례한다. 따라서 테이블 크기를 분할을 이용해 줄여서 오버헤드를 줄일 수 있다. 또 한, 분할을 이용해 각 부분을 원하는 저장 장치에 저장할 수도 있다. 자주 사용하는 레코드를 SSD에 저장하고, 덜 접근하는 레코드를 HDD에 저장할 수 있다.
데이터 사전 저장소
관계형 데이터베이스 시스템은 테이블 자체뿐만 아니라 다른 메타데이터도 저장한다. 메타데이터는 데이터 사전(data dictionary) 또는 시스템 카탈로그(system catalog)라 부르는 구조에 저장된다. 저장되는 데이터 종류는 다음과 같다.
- 테이블 이름
- 각 테이블 속성의 이름
- 속성의 도메인과 길이
- 데이터베이스에 대해 정의한 뷰의 이름과 이 뷰에 대한 정의
- 무결성 제약 조건(키 제약 조건 등)
- 사용자의 이름, 사용자의 기본 스키마, 사용자를 인증하기 위해 사용되는 비밀번호
- 각 사용자의 권한에 대한 정보
이런 메타데이터는 일반적으로 데이터베이스 내의 테이블을 사용해 저장한다. 따라서 전체 구조를 단순화하고 시스템 데이터에 대한 빠른 접근할 수 있다. 시스템 메타데이터를 테이블로 어떻게 나타낼지에 대한 세부 사항은 시스템 설계에 따라 다르다.
데이터베이스 버퍼
서버는 메모리를 많이 필요로 하기 때문에 데이터베이스에 할당할 수 있는 메모리 양은 데이터베이스 크기보다 더 작다. 또 한, 대형 데이터베이스는 서버가 사용 가능한 전체 메모리보다 훨씬 크다. 때문에 데이터베이스 데이터는 보통 디스크에 존재하고 데이터에 대한 read, write 작업 시에만 메모리로 불러들인다. 그 후 갱신한 블록을 디스크에 다시 기록한다. 디스크에 접근하는 것은 메모리에 접근하는 것보다 훨씬 느리다. 그래서 데이터베이스 시스템의 주요 목적 중 하나는 디스크와 메모리 사이에 블록 전송 수를 최소화하는 것이다. 이를 위해서 메인 메모리에 블록을 저장하기 위한 공간을 할당하고 관리한다. 이 공간을 버퍼(buffer)라 부른다. 디스크상에 존재하는 데이터는 버퍼에 존재하는 데이터보다 더 오래된 버전일 수 있다. 버퍼 공간 할당을 책임지는 서브시스템을 버퍼 관리자(buffer manager)라 부른다.
버퍼 관리자
데이터베이스 시스템 내의 프로그램은 디스크로부터 블록을 가져와야 하면 버퍼 관리자에게 문의한다. 만약 요청한 블록이 버퍼에 존재하면 블록 주소를 전달한다. 없다면 블록을 저장하기 위한 공간을 할당하고 디스크로부터 블록을 읽어서 메인 메모리의 블록 주소를 전달한다. 이때 공간 할당을 위해 기존 블록을 디스크로 보내기도 한다. 보내진 브록은 디스크에 존재하는 최신 버전과 비교해 변경 부분을 디스크에 쓴다. 버퍼 관리자의 이런 행위는 블록을 요청을 프로세스가 인지하지 못하게 실행된다.
버퍼 교체 전략
버퍼에 남아있는 공간이 없어서 기존 블록을 제거할 때, 대부분의 운영체제는 LRU(Least Recently Used - 최근에 가장 덜 쓰인 블록 제거) 방법을 사용한다.
버퍼에 고정된 핀 블록
메모리에 올라온 블록을 프로세스가 read/write 하고 있을 때 다른 동시 프로세스(concurrent process)가 그 블록을 다른 블록으로 교체하거나 데이터를 write 하는 것은 부정확한 데이터 사용, 블록 손실을 야기한다. 따라서 프로세스가 버퍼 블록을 읽기 전에 블록을 고정하는 핀(pin) 연산을 실행한다. 데이터 읽기가 끝나면 프로세스는 고정을 해체하는 언핀(unpin) 연산을 실행한다. 복수의 프로세스가 같은 블록에서 데이터를 읽을 수 있다. 이 경우 각 프로세스가 각자의 핀 연산을 실행하게 된다. 때문에 핀 연산을 한 모든 프로세스가 읽기를 끝내고 언핀 연산을 실행한 후에야 해당 블록을 다른 블록으로 교체할 수 있다.
버퍼에 대한 공유 및 독점적 잠금
데이터베이스 버퍼 관리자는 프로세스가 버퍼에 대한 공유 잠금 또는 독점적 잠금을 얻을 수 있게 해준다. 버퍼 관리자가 제공하는 잠금 시스템은 데이터베이스 프로세스가 블록에 접근하기 전에 공유 모드(shared mode) 또는 독점적 모드(exclusive mode)에서 버퍼 블록을 잠금하고 접근이 완료된 후 잠금을 해제할 수 있게 한다. 잠금에 대한 규칙은 다음과 같다.
- 임의의 수의 프로세스가 동시에 어떤 블록에 대한 공유 잠금을 가질 수 있다.
- 한 번에 하나의 프로세스만 독점적 잠금을 얻을 수 있다. 독점적 잠금을 얻었다면 다른 프로세스들은 블록에 대해 공유 잠금을 가질 수 없다. 때문에 다른 프로세스가 버퍼 블록에 대해 잠금을 가지지 않는 경우에만 독점적 잠금을 가질 수 있다.
- 블록에 이미 독점적 잠금이 있는 상태에서 다른 프로세스가 잠금을 요청하면 이전의 모든 잠금이 해제될 때까지 해당 블록에 대한 요청을 보류 상태로 유지한다.
- 블록이 잠금 상태가 아니거나 이미 공유 잠금 상태에서 프로세스가 해당 블록에 공유 잠금을 요청하면 그 공유 잠금은 허용된다.
잠금은 다음과 같이 획득되고 해제된다.
- 블록에 대한 작업 실행 전에 핀을 진행해야 한다. 잠금은 그 후에 획득되고 언핀하지 전에 해제해야 한다.
- 버퍼 블록에서 데이터를 읽기 전에 프로세스는 블록에 대한 공유 잠금을 얻어야 한다. 데이터 읽기가 완료되면 프로세스는 잠금을 해제해야 한다.
- 버퍼 블록의 내용을 갱신하기 전에 프로세스는 블록에 대한 독점적 잠금을 얻어야 한다. 갱신이 완료된 후에 잠금을 해제해야 한다.
버퍼 교체 전략
위에서 데이터베이스는 버퍼 교체를 위해 LRU를 사용한다고 설명했다. 데이터베이스 시스템은 LRU를 사용할 때 사용자 요청을 처리하는 몇 가지 절차를 살펴봄으로써 앞으로 어느 블록을 사용할지 미리 결정할 수 있다. 따라서 향후 참조될 블록을 좀 더 정확히 예측할 수 있다. 데이터베이스 버퍼 교체 전략을 설명하기 위해 다음과 같은 SQL 질의문을 처리한다고 가정해 보자.
1
select * from instructor natural join department;
이 질의문의 전략을 서술한 의사코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for each tuple i of instructor do
for each tuple d of department do
if i[dept_name] = d[dept_name]
then begin
let x be a tuple defined as follos:
x[ID] := i[ID]
x[dept_name] := i[dept_name]
x[name] := i[name]
x[salary] := i[salary]
x[buliding] := i[building]
x[budget] := i[budge]
include tuple x as part of result of instructor ⋈ department
end
end
end
이 예시에서 instructor 레코드는 한번 처리가 완료되면 다시 사용하지 않는다. 따라서 버퍼 관리자는 instructor 마지막 레코드가 처리되면 instructor 블록이 차지하던 공간을 비운다. 이렇게 특정 블록의 레코드에 대한 모든 처리가 끝나면 즉시 블록을 제거하는 방법을 즉시 전달 (toss-immediate)방법이라 한다. 또 한, department 레코드를 포함한 블록의 경우 instructor 각 레코드에 대해 department 블록을 모두 조사해야 한다. 즉, 최근에 가장 많이 사용된 블록 다음으로 재참조할 블록은 최근에 가장 덜 사용한 블록이 된다. 결국 LRU가 아닌 MRU(Most Recently Used)를 사용한다. 이때, 현재 처리 중인 블록 가장 많이 실행된 블록을 치환하면 안되므로 MRU의 올바른 동작을 위해선 핀을 사용해야 한다. 언핀하면 이 블록이 최근에 가장 많이 사용한 블록이 된다. 처리 중인 요청에 대해 시스템이 가지고 있는 지식을 추가로 사용하면 버퍼 관리자는 어떤 요청이 특정 레코드를 참조할 것이라는 확률에 대한 통계 정보도 사용할 수 있다. 예를 들어 데이터 파일에 대한 인덱스는 인덱스된 파일 자체보다 더 많이 접근한다. 따라서 버퍼 관리자는 다른 방법을 사용할 수 있다면 인덱스 블록을 메인 메모리에서 제거하면 안 된다.
쓰기 및 복구의 재정렬
데이터베이스 버퍼를 사용하면 나중에 쓰기가 수행된 순서와 다른 순서로 메모리 내에서 데이터 쓰기를 수행한 뒤 나중에 디스크에 반영할 수 있다. 또 한, 파일 시스템은 쓰기 작업을 정기적으로 재정렬한다. 이런 재정렬은 시스템 충돌 발생 시 디스크에 있는 데이터의 일관성을 깨트릴 수 있다. 파일 시스템이 각 파일 블록을 추적하기 위해 연결 리스트를 사용하고 다음과 같은 절차를 통해 새로운 블록을 삽입한다고 해보자
- 새 노드에 대한 데이터를 작성한다
- 이전 노드의 포인터를 갱신한다
- 리스트 끝에 새노드를 삽입한다
위 과정에서 첫 번째 과정이 실행되기 전에 쓰기 순서가 재정렬되어 포인터를 먼저 갱신한다고 하자. 이때 시스템이 충돌하면 새로운 노드는 없어지므로 데이터 구조가 손상된다. 이 문제를 해결하기 위해 이전 파일 시스템은 시스템 재시작 시 파일 시스템 일관성 검사(file system consistency check)를 통해 데이터 구조의 일관성을 확인했다. 일관성이 깨졌다면 일관성 복원을 위해 추가 조치를 취했다. 하지만 일관성 검사에 소요되는 시간은 디스크 시스템 용량에 비례하기에 많은 시간이 소요된다. 현대 파일 시스템은 쓰기 작업이 수행되는 순서대로 로그를 저장하기 위해 디스크를 할당한다. 이런 디스크를 로그 디스크(log disk)라고 한다. 각 쓰기에 대해 쓰기를 수행했던 순서대로 쓸 블록 번호와 쓸 데이터를 가진다. 로그 디스크에 대한 모든 접근은 순차적이므로 기본적으로 탐색 시간이 필요 없으며(디스크 seek time과 rotation time이 필요 없다) 연속된 여러 블록을 한꺼번에 쓸 수도 있다. 때문에 로그 디스크 쓰기는 일반 디스크에 임의 순서로 쓰는 것보다 속도가 몇 배나 빠르다. 디스크 실제 위치 상에도 데이터를 기록해야 하지만, 디스크 암 이동 최소화를 위해 쓰기 순서를 변경할 수도 있기 때문에 실제 데이터 기록은 나중에 이뤄질 수도 있다. 실제 디스크 위치에 쓰기를 완료하지 못하고 충돌이 발생하면, 시스템 백업 시 로그 디스크를 읽어 완료하지 않은 쓰기 작업을 수행한다. 쓰기 작업을 모두 마치면 로그 디스크에서 그 레코드를 삭제한다. 이렇게 로그 디스크를 지원하는 파일 시스템을 저널링 파일 시스템(journaling file system)이라고 한다. 저널링 파일 시스템은 별도의 로그 디스크 없이도 구현할 수 있고 데이터와 로그를 같은 디스크에 보관할 수 있다. 이 방식을 사용하면 성능이 저하되지만 금전적 비용을 절감할 수 있다.
메인 메모리 데이터베이스(main-memory database)의 저장 구조
현대의 메인 메모리 크기는 충분히 크고 저렴해서 전체 데이터베이스를 버퍼에 적재해 디스크 I/O를 피할 수 있다. 즉 데이터가 완전히 메모리에 존재하게 된다. 이를 이용해 저장 장치 구조 및 데이터베이스 자료 구조를 잘 설계해 성능을 향상시킬 수 있다. 메인 메모리 데이터베이스는 모든 데이터가 메모리에 상주하는 데이터베이스다. 메인 메모리 데이터베이스는 모든 데이터가 메모리에 존재한다는 점을 이용해 성능을 최적화했고 버퍼 관리자가 존재하지 않는다. 메모리 상주(memory-resident) 데이터로 인해 다음과 같은 최적화를 할 수 있다. 우선 디스크 기반 데이터베이스는 레코드 포인터를 이용해 다음과 같이 레코드에 접근해야 한다.
- 레코드가 블록에 저장되고 레코드에 대한 포인터는 블록 식별자와 블록 내의 오프셋 또는 슬롯 번호로 구성된다.
- 레코드 포인터를 사용하기 위해서 블록이 버퍼에 있는지 확인한다
- 블록이 존재하면 버퍼에서 위치를 찾는다
- 없다면 디스크에서 가져온다
위 과정 수행엔 상당수의 CPU 사이클이 필요하다. 반면 메인 메모리 데이터베이스는 레코드에 대한 직접 포인터(direct pointer)를 메모리에 가지고 있을 수 있어서 접근이 빠르다. 만약 slotted-page structure를 블록 내에서 사용해 레코드를 저장한다면 직접 포인터를 사용하는 대신 slotted-page 헤더에 있는 엔트리를 통해 우회해 접근하면 된다. 다만 slotted-page strucutre는 프로세스가 읽기를 하는 도중 해당 레코드 이동 방지를 위해 블록에 대해 락을 걸어야 하는 오버헤드가 존재한다. 때문에 많은 메인 메모리 데이터베이스는 이 방식을 사용하지 않는다. 대신에 메인 메모리에 레코드를 직접 할당하고 다른 레코드에 대한 갱신으로 인해 레코드를 이동하지 않게 한다. 이 방식은 가변 크기 레코드를 반복적으로 삽입 삭제 시 단편화가 진행된다는 문제를 가지지만 주기적으로 메모리 압축을 수행해서 단편화를 방지할 수 있다.