배치 애플리케이션이란?
배치 애플리케이션이란 사람의 개입 없이 자동으로 대량의 데이터를 처리하는 애플리케이션을 의미합니다. 따라서 에러 발생 시 사람이 판단해 복구할 수 없기 때문에 배치 애플리케이션은 신뢰성 있고 견고해야 합니다. 또 한, 처리할 데이터가 많을 처리 완료까지 더 많은 시간이 필요합니다. 만약 배치 애플리케이션을 제한된 시간 내에 끝내야 한다면 퍼포먼스 역시 고려해야 합니다. 종합적으로 배치 애플리케이션은 다음과 같은 요구사항을 만족해야 합니다.
- 대량의 데이터를 원활히 처리할 수 있어야 한다
- 배치 시스템이 큰 문제가 발생하지 않는 이상 사람이 개입하지 말아야 한다.
- 배치 애플리케이션은 유효하지 않은 데이터를 충돌이나 불필요한 중단 없이 처리해야 한다
- 배치 애플리케이션은 로깅, 알림 등을 통해 언제 어떤 문제가 발생했는지 지속적으로 추적해야 한다.
- 배치 애플리케이션은 주어진 시간 내에 작업을 완료해야 하며 동시에 실행되는 다른 애플리케이션에게 영향을 주지 않을 정도로 성능이 우수해야 합니다.
스프링 배치는 위와 같은 요구사항들을 만족하기 위해 ready-to-use component를 이용합니다.
스프링 배치
스프링 배치 프로젝트의 목적은 통상적인 배치 애플리케이션의 니즈를 효율적으로 해결하는 batch-oriented 오픈소스 프레임워크를 만드는 것입니다. 스프링 배치의 주요 특징은 다음과 같습니다.
 스프링 배치에 대해 공부하면서 주의해야 할 점 중 하나는 스프링 배치는 스케줄러가 아니라는 것입니다. 따라서 스프링 배치를 사용할 때는 별도의 스케줄러를 이용해 스프링 배치 런타임에 접근하거나(Quartz 사용 시) 특정 JVM 프로세스를 실행시켜야 합니다(크론을 사용할 경우).
스프링 배치는 성능 향상을 위해 청크 단위로 아이템을 처리합니다. 청크 프로세싱은 모든 데이터를 사전에 메모리에 로딩하는 대신 스트리밍 합니다. 기본적으로 청크 프로세싱은 싱글 스레드이지만 멀티 스레드를 이용하는 방식도 제공합니다. 멀티 스레드 방식을 이용해 대량의 데이터를 빠르게 처리할 수 있습니다. 멀티스레딩을 구현하는 다양한 방법이 있지만 스프링 배치에 대한 소개를 하는 글이므로 그중 partitioning이라는 방식 하나만 간단히 소개하겠습니다.
Partioning은 스탭을 여러개의 서브 스탭으로 나누고, 각 서브 스탭이 전체 데이터의 일부분을 처리하는 방식입니다. 이 방식은 입력 데이터의 구조를 알고 있고 이 데이터를 어떻게 서브 스탭에게 나눠야 할지 알고 있을 때 사용할 수 있습니다. 예컨대 대량의 레코드를 PK 기준으로 나눌 수 있습니다.
스프링 배치에 대해 공부하면서 주의해야 할 점 중 하나는 스프링 배치는 스케줄러가 아니라는 것입니다. 따라서 스프링 배치를 사용할 때는 별도의 스케줄러를 이용해 스프링 배치 런타임에 접근하거나(Quartz 사용 시) 특정 JVM 프로세스를 실행시켜야 합니다(크론을 사용할 경우).
스프링 배치는 성능 향상을 위해 청크 단위로 아이템을 처리합니다. 청크 프로세싱은 모든 데이터를 사전에 메모리에 로딩하는 대신 스트리밍 합니다. 기본적으로 청크 프로세싱은 싱글 스레드이지만 멀티 스레드를 이용하는 방식도 제공합니다. 멀티 스레드 방식을 이용해 대량의 데이터를 빠르게 처리할 수 있습니다. 멀티스레딩을 구현하는 다양한 방법이 있지만 스프링 배치에 대한 소개를 하는 글이므로 그중 partitioning이라는 방식 하나만 간단히 소개하겠습니다.
Partioning은 스탭을 여러개의 서브 스탭으로 나누고, 각 서브 스탭이 전체 데이터의 일부분을 처리하는 방식입니다. 이 방식은 입력 데이터의 구조를 알고 있고 이 데이터를 어떻게 서브 스탭에게 나눠야 할지 알고 있을 때 사용할 수 있습니다. 예컨대 대량의 레코드를 PK 기준으로 나눌 수 있습니다.

스프링 배치의 read와 write
스프링 배치에서 데이터를 읽어와 파싱하고 쓰는 시나리오는 아주 흔합니다. 때문에 스프링 배치는 이와 관련된 컴포넌트들을 제공하고 있습니다. 또 한, chunk processing이라는 batch-oriented 알고리즘을 통해 플로우 실행을 관리합니다. chunk processing, ItemReader와 ItemWriter를 이용한 read-write 기본 시나리오는 다음과 같습니다. ItemReader와 ItemWriter는 스프링 배치에서 read-write 시나리오를 위해 제공하는 인터페이스입니다.
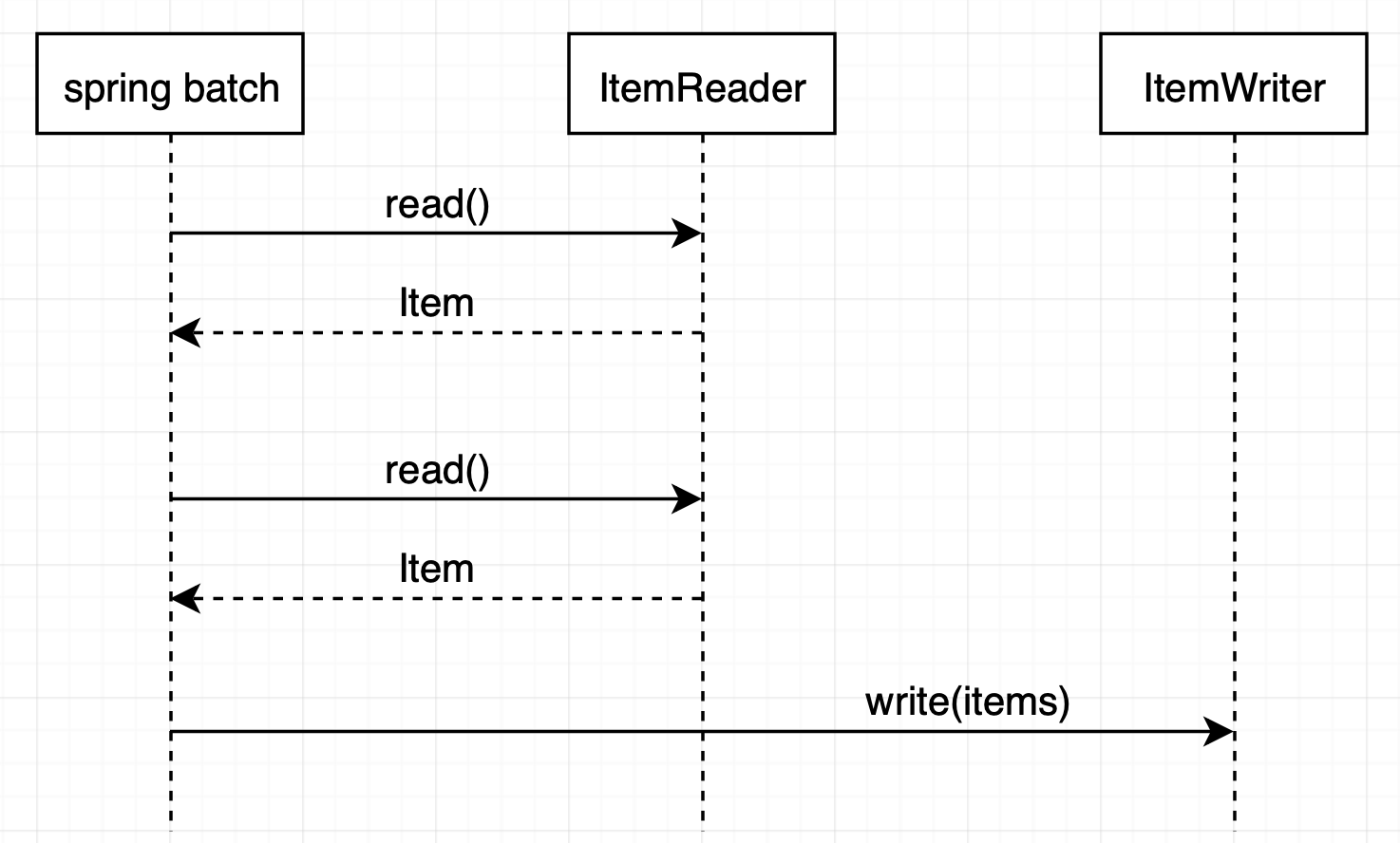 스프링 배치는 item reader를 이용해 아이템을 사전에 설정한 청크 크기가 찰 때까지 한 번에 하나씩 읽어들입니다. 그 후, 청크를 item writer에게 보냅니다. 이 과정은 입력을 모두 읽을 때까지 지속됩니다.
청크 프로세싱은 job이 사용하는 아이템들을 모두 한 번에 작업하는 것이 아닌 작은 청크 단위로 처리하기 때문에 대량의 데이터를 처리하기가 유리합니다. 즉, 대용량 파일을 메모리에 모두 로드하는 것이 아닌 스트림으로 처리하기 때문에 메모리를 더 효율적으로 사용합니다. 청크 프로세싱은 job의 데이터 플로우를 더 유연하게 관리하게 해줍니다. 또 한, 스프링 배치는 read-write 연산과 관련된 트랜잭션과 에러 핸들링도 관여합니다.
만약 read-write 시나리오에서 read 한 데이터를 원하는 형식으로 변환해 ItemWriter에게 전달해야 한다면, ItemProcessor 인터페이스를 구현한 컴포넌트를 사용하면 됩니다. read-writer 시나리오에서 데이터 변환은 옵션 입니다.ItemProcesstor를 사용한 플로우는 다음과 같습니다.
스프링 배치는 item reader를 이용해 아이템을 사전에 설정한 청크 크기가 찰 때까지 한 번에 하나씩 읽어들입니다. 그 후, 청크를 item writer에게 보냅니다. 이 과정은 입력을 모두 읽을 때까지 지속됩니다.
청크 프로세싱은 job이 사용하는 아이템들을 모두 한 번에 작업하는 것이 아닌 작은 청크 단위로 처리하기 때문에 대량의 데이터를 처리하기가 유리합니다. 즉, 대용량 파일을 메모리에 모두 로드하는 것이 아닌 스트림으로 처리하기 때문에 메모리를 더 효율적으로 사용합니다. 청크 프로세싱은 job의 데이터 플로우를 더 유연하게 관리하게 해줍니다. 또 한, 스프링 배치는 read-write 연산과 관련된 트랜잭션과 에러 핸들링도 관여합니다.
만약 read-write 시나리오에서 read 한 데이터를 원하는 형식으로 변환해 ItemWriter에게 전달해야 한다면, ItemProcessor 인터페이스를 구현한 컴포넌트를 사용하면 됩니다. read-writer 시나리오에서 데이터 변환은 옵션 입니다.ItemProcesstor를 사용한 플로우는 다음과 같습니다.

Spring batch main component
이제 스프링 배치의 메인 컴포넌트를 살펴보겠습니다. 스프링 배치의 메인 컴포넌트들은 다음과 같이 infrastructure component(Job repository, Job launcher)와 application component로 나누어져 있습니다. 스프링 배치는 infrastructure component 들에 대한 구현을 제공합니다.
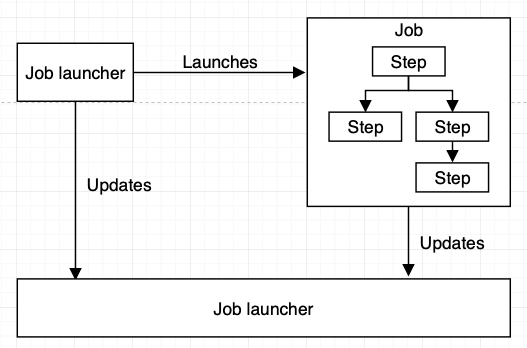 애플리케이션 컴포넌트는 job과 사용자가 구현해야 할 부분으로 나누어누 있습니다. 위에서 살펴보았듯 스프링 배치는 ItemReader, ItemWriter 등의 컴포넌트를 제공합니다. 사용자는 이들을 implements 해서 필요한 로직을 구현해야 합니다.
스프링 배치가 제공하는 메인 컴포넌트들을 간단히 정리해 보면 다음과 같습니다.
애플리케이션 컴포넌트는 job과 사용자가 구현해야 할 부분으로 나누어누 있습니다. 위에서 살펴보았듯 스프링 배치는 ItemReader, ItemWriter 등의 컴포넌트를 제공합니다. 사용자는 이들을 implements 해서 필요한 로직을 구현해야 합니다.
스프링 배치가 제공하는 메인 컴포넌트들을 간단히 정리해 보면 다음과 같습니다.

spring batch와 외부 애플리케이션
스프링 배치는 외부에서 어떤 이벤트가 트리거 역할을 해주어야 배치를 실행할 수 있습니다. 이 트리거의 예로는 스케줄러, 스프링 배치를 실행시키는 스크립트 등이 있습니다.
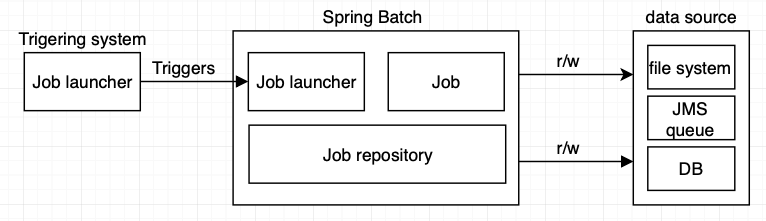 job이 응답을 위한 작업을 시작했다면, 우선 JobLauncher와 JobParameters를 사용해 Job을 제어합니다. 또 한, 스프링 배치는 파일 시스템, 데이터베이스 등 다양한 데이터를 데이터 소스로 사용할 수 있습니다.
job이 응답을 위한 작업을 시작했다면, 우선 JobLauncher와 JobParameters를 사용해 Job을 제어합니다. 또 한, 스프링 배치는 파일 시스템, 데이터베이스 등 다양한 데이터를 데이터 소스로 사용할 수 있습니다.Spring Batch infrastructure
Spring batch infrastructure는 배치 job을 시작하는 컴포넌트와 job execution 메타데이터를 저장하는 컴포넌트로 나뉩니다. 스프링 배치를 하기 위해 이 컴포넌트들을 직접 구현할 필요는 없지만, 이에 관련된 몇 가지 설정들을 해주어야 합니다.
Job 실행과 Job 메타데이터 저장
위에서 언급한 job launcher와 job repository는 실제로 JobLauncher, JobRepository라는 인터페이로 구현돼 있습니다. JobLauncher는 스프링 배치 job을 시작하는 엔트리 포인트입니다.
1
2
3
4
5
6
package org.springframework.batch.core.launch;
public interface JobLauncher {
// Job은 스프링 빈 설정에 의해 성되고 JobParameter는 스프링 배치 시작 매커니즘에 의해 생성됩니다.
public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
JobLauncher는 job을 동기 또는 비동기로 처리할지 등의 시작(launching) 전략을 캡슐화합니다. 스프링 배치는 자체적으로 SimpleJobLauncher라는 JobLauncher 구현체를 제공합니다. SimpleJobLauncher는 작업을 생성하지 않고 오직 시작하기만 합니다. Job 생성은 job repository에 위임합니다. Job repository는 job 실행에 대한 모든 metadata를 관리합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
package org.springframework.batch.core.repository;
public interface JobRepository {
boolean isJobInstanceExists(String jobName, JobParameters jobParameters);
JobInstance createJobInstance(String jobName, JobParameters jobParameters);
JobExecution createJobExecution(JobInstance jobInstance, JobParameters jobParameters, String jobConfigurationLocation);
JobExecution createJobExecution(String jobName, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException;
void update(JobExecution jobExecution);
void add(StepExecution stepExecution);
void addAll(Collection<StepExecution> stepExecutions);
void update(StepExecution stepExecution);
void updateExecutionContext(StepExecution stepExecution);
void updateExecutionContext(JobExecution jobExecution);
@Nullable
StepExecution getLastStepExecution(JobInstance jobInstance, String stepName);
int getStepExecutionCount(JobInstance jobInstance, String stepName);
@Nullable
JobExecution getLastJobExecution(String jobName, JobParameters jobParameters);
}
JobRepository는 batch job에 대한 생성, 업데이트 등 batch job을 관리하는 모든 기능들을 제공합니다. job launcher는 job 생성을 Job repository에게 위임하고 job은 실행 도중 job repository를 호출해 현재 상태를 저장합니다. 이 때문에 job이 어떻게 실행되었는지, 실패 지점이 어디고 어디부터 재시작해야 하는지를 알 수 있습니다. 스프링 배치는 JobRepository에 대해 두 가지 구현 방식을 제공합니다. 하나는 메모리를 사용한 방식으로 모니터링과 재시작이 불필요하거나 테스트에 사용할 수 있습니다. 또 하나는 RDB를 사용한 방식입니다.
Spring Batch Infrastructure를 데이터베이스에 설정하기
스프링 배치는 job repository 영속화를 위해 다음과 같은 기능들을 제공합니다.
- 많이 사용하는 데이터베이스 엔진들로 필요한 데이터베이스 테이블을 생성할 수 있는 SQL 스크립트
- job repository 테이블을 조작할 수 있는 SQL 문을 실행하는 JobRepository 구현체(SimpleJobRepository)
job repository에 관한 데이터베이스 테이블 생성하기 테이블 생성에 필요한 스크립트는 스프링 배치 의존성 내부에 존재합니다. 패키지 경로는 org.springframework.batch.core 입니다. 이 sql 파일들은 크게 테이블 생성을 위한 “schema-[database name].sql”과 테이블 삭제를 위한 “schema-drop-[database name].sql”로 나뉩니다. schema-mysql.sql 파일 내부는 다음과 같습니다. 자신이 사용하고자 하는 데이터베이스에 대한 스크립트에 접근하고 복사해 사용하면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
...
Job Repository 설정 Job Repository는 @EnableBatchProcessing을 사용하면 자동으로 설정됩니다. @EnableBatchProcessing은 스프링 배치를 시작하기 위한 기본 설정을 제공해 주는 역할을 하고 JobRepository뿐만 아니라 JobLauncher, JobBuilderFactory 등 spring batch infrastructure 컴포넌트들을 자동으로 설정해 줍니다. 따라서 RDB를 사용한다면 다음과 같이 application.yml 파일을 설정한 뒤 스프링 부트를 사용할 수 있습니다.
1
2
3
4
5
6
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: ...
username: ...
password: ...
스프링 배치 기본 예제는 다음과 같습니다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Slf4j
@Configuration
@EnableBatchProcessing
public class ExampleJobConfig {
public JobBuilderFactory jobBuilderFactory;
public StepBuilderFactory stepBuilderFactory;
public ExampleJobConfig(final JobBuilderFactory jobBuilderFactory, final StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job exampleJob() {
return jobBuilderFactory.get("exampleJob")
.start(step())
.build();
}
@Bean
public Step step() {
return stepBuilderFactory.get("step")
.tasklet((contribution, chunkContext) -> {
log.info("Step!");
return RepeatStatus.FINISHED;
})
.build();
}
}
Job 살펴보기
Job은 배치 애플리케이션의 중심 개념입니다. 이 글에서는 Job을 정적 모델링 측면과 동적 런타임 측면으로 살펴보고자 합니다.
Step으로 Job 모델링 하기
스프링 패치 Job은 일련의 step입니다. 예컨대, product에 대한 job 하나를 다음과 같이 decompress(입력으로 온 압파일 해제), read-write, cleanup(압축 해제한 파일 삭제)으로 나눌 수 있습니다(총 3개의 step).
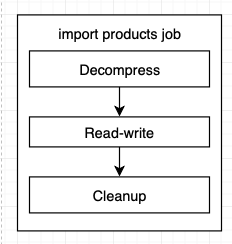 이 예시를 코드로 작성하면 다음과 같습니다.
이 예시를 코드로 작성하면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
@Slf4j
@EnableBatchProcessing
@Configuration
public class LinearFlowJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public LinearFlowJob(final JobBuilderFactory jobBuilderFactory, final StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job job() {
return jobBuilderFactory.get("linear flow job")
.start(decompress())
.next(readWrite())
.next(cleanTasklet())
.build();
}
@Bean
public Step decompress() {
return stepBuilderFactory.get("decompress")
.tasklet((contribution, chunkContext) -> {
log.info("decompress file");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step readWrite() {
return stepBuilderFactory.get("read-write")
.chunk(100)
.reader(() -> {
log.info("read");
return null;
})
.writer((items) -> items.forEach(item -> log.info(item + "\n")))
.build();
}
@Bean
public Step cleanTasklet() {
return stepBuilderFactory.get("clean")
.tasklet((contribution, chunkContext) -> {
log.info("clean tasklet");
return RepeatStatus.FINISHED;
})
.build();
}
}
이렇게 Job을 여러 개의 step으로 나누면 테스트에 용이하고 재사용하기 쉬우며 유지 보수가 쉽습니다.
Job이 무조건 여러 개의 step으로 이루어진 하나의 과정만 가질 수 있는 것은 아닙니다. 스프링 배치는 이전 스탭의 상태(compeleted, failed)나 커스텀 로직에 따라 control flow를 결정하는 기능도 제공합니다. 이를 통해 필요한 Job에 대한 제어를 어디까지 할지 결정할 수 있기 때문에 견고하면서도 유연한 Job을 만들 수 있습니다. 위에서 보았던 product job에 control flow를 사용한 예시는 다음과 같습니다.
 이 예시를 코드로 작성한면 다음과 같습니다.
이 예시를 코드로 작성한면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
// NonLearFlow.java
@Configuration
@EnableBatchProcessing
@Slf4j
public class NonLinearFlow {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public NonLinearFlow(final JobBuilderFactory jobBuilderFactory, final StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job nonlinearJob() {
return jobBuilderFactory.get("non-linear job")
.start(decompressStep())
.next(readWriteStep())
.next(decider())
.from(decider())
.on(FlowExecutionStatus.COMPLETED.getName())
.to(sendReport())
.from(decider())
.on("*")
.to(clean())
.end()
.build();
}
@Bean
public Step decompressStep() {
return stepBuilderFactory.get("decompress step")
.tasklet((contribution, chunkContext) -> {
log.info("decompress step");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step readWriteStep() {
return stepBuilderFactory.get("read write step")
.<String, String>chunk(100)
.reader(new ListItemReader<>(List.of("a", "b", "c")))
.writer((items) -> items.forEach(item -> log.info(item + "\n")))
.build();
}
@Bean
public JobExecutionDecider decider() {
return new SimpleDecider();
}
@Bean
public Step generateReport() {
return stepBuilderFactory.get("generate report")
.tasklet((contribution, chunkContext) -> {
log.info("generate report");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step sendReport() {
return stepBuilderFactory.get("send report")
.tasklet((contribution, chunkContext) -> {
log.info("send report");
return RepeatStatus.FINISHED;
})
.build();
}
@Bean
public Step clean() {
return stepBuilderFactory.get("clean")
.tasklet((contribution, chunkContext) -> {
log.info("clean");
return RepeatStatus.FINISHED;
})
.build();
}
}
// SimpleDecider.java
public class SimpleDecider implements JobExecutionDecider {
private static final Random random = new Random();
@Override
public FlowExecutionStatus decide(final JobExecution jobExecution, final StepExecution stepExecution) {
int number = random.ints(1, 10)
.findFirst()
.orElseThrow(IllegalArgumentException::new);
if (number <= 5) {
return FlowExecutionStatus.COMPLETED;
}
return FlowExecutionStatus.FAILED;
}
}
스프링 배치는 Step 인터페이스를 제공하고 FlowStep, JobStep, PartitionStep, TaskletStep과 같은 Step의 구현체도 제공합니다. 이 중 애플리케이션 개발자가 신경 써야 하는 구현체는 TaskletStep입니다. TaskletStep은 tasklet에게 처리를 위임합니다. tasklet 인터페이스는 execute라는 하나의 메서드만 가지며 work의 한 부분을 처리합니다. step을 생성하는 것은 tasklet을 구현하거나 스프링 배치가 제공하는 구현을 사용하는 것입니다. 어떤 처리를 해야 할 때 기본적으로 TaskLet을 사용하면 됩니다. 만약 위에서 언급한 read-process-write 배치 패턴을 따라야 한다면, TaskLet보다는 chunk를 사용하는 것이 더 효율적입니다.
Job 인스턴스와 Job execututions 실행하기
배치 프로세스는 데이터를 자동으로 핸들링하기 때문에 이에 대한 모니터링을 해야 합니다. 그래야 문제가 발생했을 때, job을 문제 발생 지점부터 재시작할지 처음부터 다시 시작할지를 결정할 수 있습니다. 이를 위해선 각 job 실행을 구분할 수 있어야 하며 job 실행 도중 행한 모든 것을 저장해야 합니다. 이 기능 또한 스프링 배치에서 제공해 주고 있습니다.
Job, Job Instance, Job Execution
위에서 Job을 일련의 step으로 구성된 배치 프로세스라 정의했습니다. 스프링 배치는 이런 Job뿐만 아니라 job instance, job execution이라는 개념도 사용하고 있습니다. 이들은 모두 프레임워크가 job을 런타임에 핸들링하는 방식과 관련 있습니다. Job, Job instance, Job execution 차이는 다음과 같습니다.
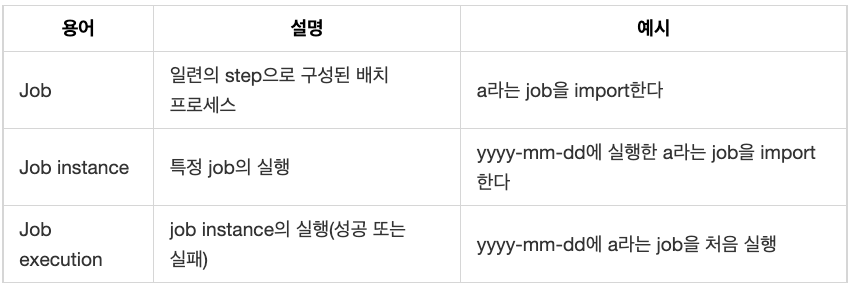 즉, job은 여러 개의 job instance를, job instance는 여러 개의 job execution을 가질 수 있습니다.
즉, job은 여러 개의 job instance를, job instance는 여러 개의 job execution을 가질 수 있습니다.
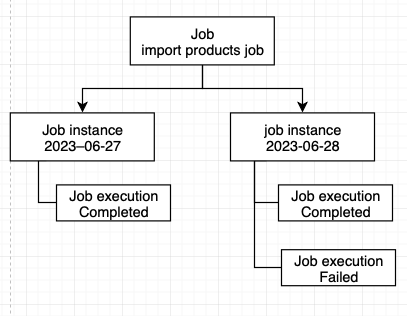 job instance는 job과 job parameter로 이루어져 있습니다. 예를 들어 yyyy-mm-dd에 실행할 a라는 job의 인스턴스라 할 때 yyyy-mm-dd는 job instance를 정의하는 파라미터입니다. 즉, job parameter는 job instance를 식별하기 위해 사용됩니다. Job paramter로 사용할 수 있는 데이터 타입은 Date, String, Long, Double이 있습니다.
job instance와 job execution 라이프 사이클은 다음과 같은 규칙을 따릅니다.
job instance는 job과 job parameter로 이루어져 있습니다. 예를 들어 yyyy-mm-dd에 실행할 a라는 job의 인스턴스라 할 때 yyyy-mm-dd는 job instance를 정의하는 파라미터입니다. 즉, job parameter는 job instance를 식별하기 위해 사용됩니다. Job paramter로 사용할 수 있는 데이터 타입은 Date, String, Long, Double이 있습니다.
job instance와 job execution 라이프 사이클은 다음과 같은 규칙을 따릅니다.
- 처음으로 job을 실행하면, 스프링 배치는 그에 관한 job instance와 job execution을 생성합니다.
- 만약 하나의 instance가 job을 정상적으로 끝냈다면, 같은 job instance를 다시 실행할 수 없습니다.
- 같은 instance를 동시에 여러 번 실행할 수 없습니다.