파일 시스템 개요
컴퓨터 시스템에서 파일을 보관하기 위해 2차 메모리를 사용합니다. 운영체제는 파일 훼손 등을 막기 위해 사용자가 직접 파일에 대해 접근하는 것을 막습니다. 그리고 파일을 보관하고 관리하는 파일 관리자를 두어 저장 장치를 관리하는 데 이를 파일시스템이라 합니다. 파일 관리자는 파일 테이블을 사용해 파일에 대한 CRUD를 수행합니다. 또 한, 사용자가 파일을 사용하고자 할 때 읽기, 쓰기, 실행 같은 다양한 접근 방법을 제공합니다. 사용자가 특정 파일에 접근하기 위해선 파일 관리자로부터 파일에 접근할 수 있는 권한을 얻어야 합니다. 이 권한을 파일 디스크립터(file descriptor)라고 합니다.
파일 시스템의 기능
파일 테이블의 구성은 운영체제마다 다릅니다. 윈도우의 경우 FAT, NTFS 형식을 사용하고 유닉스의 경우 I-node 형식을 사용합니다. 파일 테이블 구성은 파일 시스템은 다르지만 다음과 같은 공통 기능을 수행합니다. 파일시스템은 여러 종류의 파일을 구분하기 위해 파일 이름과 확장자를 만들어 관리합니다. 파일에 관한 다양한 정보는 파일 헤더에 저장해 관리합니다.

블록과 파일 테이블
데이터는 운영체제와 저장 장치 간에 블록 단위로 전송됩니다. 블록은 저장 장치에서 사용하는 가장 작은 단위로, 한 블록에 주소하가 할당됩니다. 메인 메모리는 보통 수 기가바이트이고 디스크는 수 테라바이트이기 때문에 디스크 섹터마다 주소를 부여하면 너무 많은 양의 주소가 필요합니다. 때문에 파일 관리자는 여러 섹터를 묶어서 하나의 블록으로 만들고 블록 하나에 주소 하나를 배정합니다.
블록 크기는 시스템마다 다릅니다. 사용자는 포맷을 할 때 기본 블록 크기를 사용할 수도 있고 주어진 범위 내에서 직접 지적할 수도 있습니다. 블록 크기를 작게 설정하면 내부 단편화 현상이 줄어들어서 저장 장치를 효율적으로 사용할 수 있습니다. 하지만 파일이 여러 블록으로 나누어져서 파일 입출력 속도가 느려집니다. 포맷을 하면 각 블록에 번호가 매겨지고 파일 테이블에는 파일이 어떤 블록에 있는지 명시됩니다.
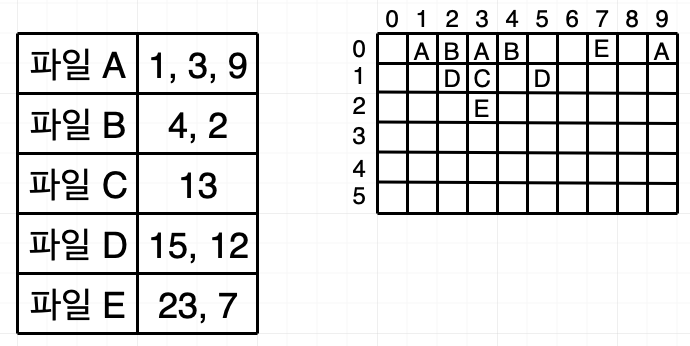
파일 분류와 확장자
파일은 논리적인 데이터 집합으로 2차 메모리에 저장됩니다. 모든 파일은 0과 1의 비트 패턴으로 이루어지며, 운영체제 입장에서는 크게 실행파일과 데이터 파일로 나뉩니다.
- 실행 파일: 운영체제가 메모리로 가져와 CPU를 이용해 작업을 하는 파일입니다. 사용자의 요청으로 프로세스가 된 파일을 의미합니다.
- 데이터 파일: 실행 파일이 작업하는 데 필요한 데이터를 모아놓은 파일입니다. 데이터 파일은 스스로 프로세스가 될 수 없습니다. 운영체제는 데이터 파일을 전송하거나 보관하기만 합니다.
파일 이름과 연결 프로그램
파일 이름과 관련해 다음과 같은 사항을 유의해야 합니다.
- 초기 운영체제의 파일 이름은 8자, 확장자는 3자로 제한돼 있었습니다.
- 파일 이름에 마침표(.)를 여러 번 사용할 경우 마지막 마침표 다음 글자를 확장자로 인식합니다.
- 파일 이름은 현재 경로 이름을 포함해 최대 255자로 표현할 수 있습니다.
- 파일 이름에는 영문자, 숫자, ‘-‘, ‘_’, ‘.’를 주로 사용합니다. 윈도우 파일에서는 일부 특수문자를 사용할 수 없고 대소문자를 구분하지 않습니다. 유닉스 파일에서는 스페이스바를 포함한 대부분의 특수문자를 사용할 수 없고 대소문자를 구분합니다.
실행파일과 데이터 파일을 더블클릭하면 모두 프로세스가 실행됩니다. 실행파일을 더블클릭하면 더블클릭한 실행파일의 프로세스가 실행됩니다. 반면 데이터 파일을 더블클릭하면 해당 데이터 파일을 필요로 하는 응용 프로그램을 운영체제가 실행합니다.
파일 속성
대부분의 파일은 다음과 같은 속성을 가지고 있습니다. 파일 속성은 각 파일 헤더에 기록되며, 운영체제는 파일 헤더를 파일 테이블에서 관리합니다.
 운영체제가 관리하는 파일 헤더 외에 데이터 파일마다 자신에게 필요한 파일 속성을 따로 정의하기도 합니다. MP3 파일의 가수명이 여기에 해당됩니다.
운영체제가 관리하는 파일 헤더 외에 데이터 파일마다 자신에게 필요한 파일 속성을 따로 정의하기도 합니다. MP3 파일의 가수명이 여기에 해당됩니다.
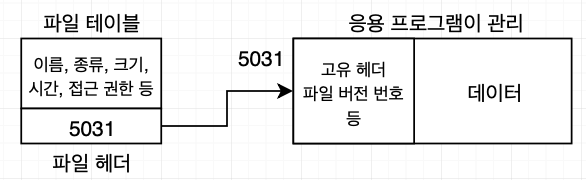 고유 헤더는 파일을 복구할 때 사용됩니다. 빠른 포맷은 파일 테이블만 지우고 실제 데이터를 지우지 않습니다. 따라서 데이터 파일의 고유 헤더는 저장 장치에 남아있어서 파일 복구 프로그램이 모든 블록을 찾아다니면서 고유 헤더에 있는 정보를 이용해 파일을 원래 상태로 복원합니다.
고유 헤더는 파일을 복구할 때 사용됩니다. 빠른 포맷은 파일 테이블만 지우고 실제 데이터를 지우지 않습니다. 따라서 데이터 파일의 고유 헤더는 저장 장치에 남아있어서 파일 복구 프로그램이 모든 블록을 찾아다니면서 고유 헤더에 있는 정보를 이용해 파일을 원래 상태로 복원합니다.
파일 작업의 유형
파일을 변경하는 것을 파일 작업 또는 파일 연산(file operation)이라고 합니다. 파일 작업은 크게 파일 자체를 변경하는 작업과 파일 내용을 변경하는 작업으로 나누어집니다.
파일 자체를 변경하는 작업
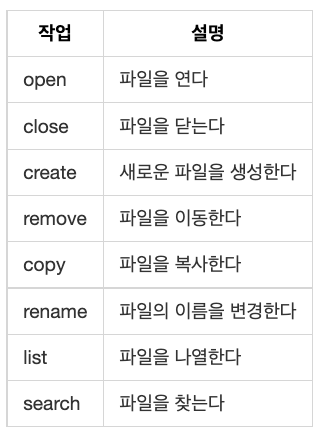 파일 내용을 변경하는 작업
파일 내용을 변경하는 작업

파일 구조
파일은 하나의 데이터 덩어리다. 파일 구조는 이 덩어리를 어떻게 구성하느냐에 따라 순차 파일 구조, 인덱스 파일 구조, 직접 파일 구조로 나누어집니다.
순차 파일 구조(sequential file structure)
일반 파일은 기본적으로 순차 파일 구조입니다. 사용자가 파일 작업을 하려면 open() 또는 create() 명령을 사용해 운영체제로부터 권한을 얻어야 합니다. 운영체제가 권한을 허가하면 파일디스크립터를 사용자에게 주는데, 이 파일 디스크립터는 파일의 맨 앞에 위치합니다. 사용자가 파일에 대해 IO 명령을 내리면 파일 디스크립터가 전진하며 특정 위치로 파일 디스크립터를 옮겨야 할 때는 lseek() 명령을 사용합니다. 순차 파일 구조의 장단점은 다음과 같습니다.
- 장점
- 모든 데이터가 순서대로 기록되기 때문에 저장 공간에 낭비되는 부분이 없습니다.
- 구조가 단순해서 테이프는 물론 플로피디스크나 메모리를 이용한 저장 장치에도 적용할 수 있습니다
- 순서대로 데이터를 읽거나 저장할 때 매우 빠르게 처리됩니다
- 단점
- 파일에 새로운 데이터 삽입과 삭제 시 시간이 많이 소모됩니다
- 특정 데이터로 이동할 때 직접 접근이 어려워서 앞에서부터 순서대로 움직여야 합니다. 따라서 데이터 검색에 적당하지 않습니다
인덱스 파일 구조(index file structure)
순차 파일 구조에 인덱스 테이블을 추가해서 순차 접근과 직접 접근이 가능합니다. 인덱스 파일 구조는 디스크를 이용한 저장 장치가 보급되면서 개발되었습니다. 인덱스 파일은 모든 파일의 시작 부분을 가지고 있기 때문에 특정 파일에 직접 접근할 수 있습니다. 이렇게 인덱스를 이용한 접근 방식을 인덱스 순차 접근(indexed sequential access)이라 하며 이렇게 구성된 파일을 ISAM(Index Sequential Access Method) 파일이라고 합니다. 인덱스 파일 구조는 순차 접근과 직접 접근이 모두 가능합니다. 현대 파일 시스템은 인덱스 파일 구조를 사용해서 파일을 저장할 때는 순차 파일 구조로 저장하고 접근할 때는 인덱스 테이블을 보고 원하는 파일에 직접 접근합니다. 인덱스 파일 구조는 인덱스 테이블을 여러 개 만들면 다양한 접근이 가능하다는 장점을 가집니다. 이런 특징 때문에 인덱스 파일 구조는 DB 같이 데이터의 빠른 접근이 필요한 시스템에 사용됩니다.
직접 파일 구조(direct fiel structure)
직접 파일 구조는 저장하려는 데이터의 특정 값에 어떤 관계를 정의해 물리적인 주소로 바로 변환하는 파일 구조입니다. 관계를 정의할 때는 해시 함수를 사용합니다. 직접 파일 구조는 해시 함수를 이용해 주소를 변환하기 때문에 데이터 접근이 빠릅니다. 그러나 해시 함수 선정을 올바르게 해야 전체 데이터가 고르게 저장됩니다.