파이프라인
CPU가 instruction을 실행할 때 한 번에 하나의 instruction만 실행할 수 있습니다. 하나의 instruction에 대한 결과를 내놓기 위한 로직들을 한 번에 수행하고 결과를 출력 레지스터에 저장한다면 instruction 3개는 시간 흐름에 따라 다음과 같이 수행될 것입니다.
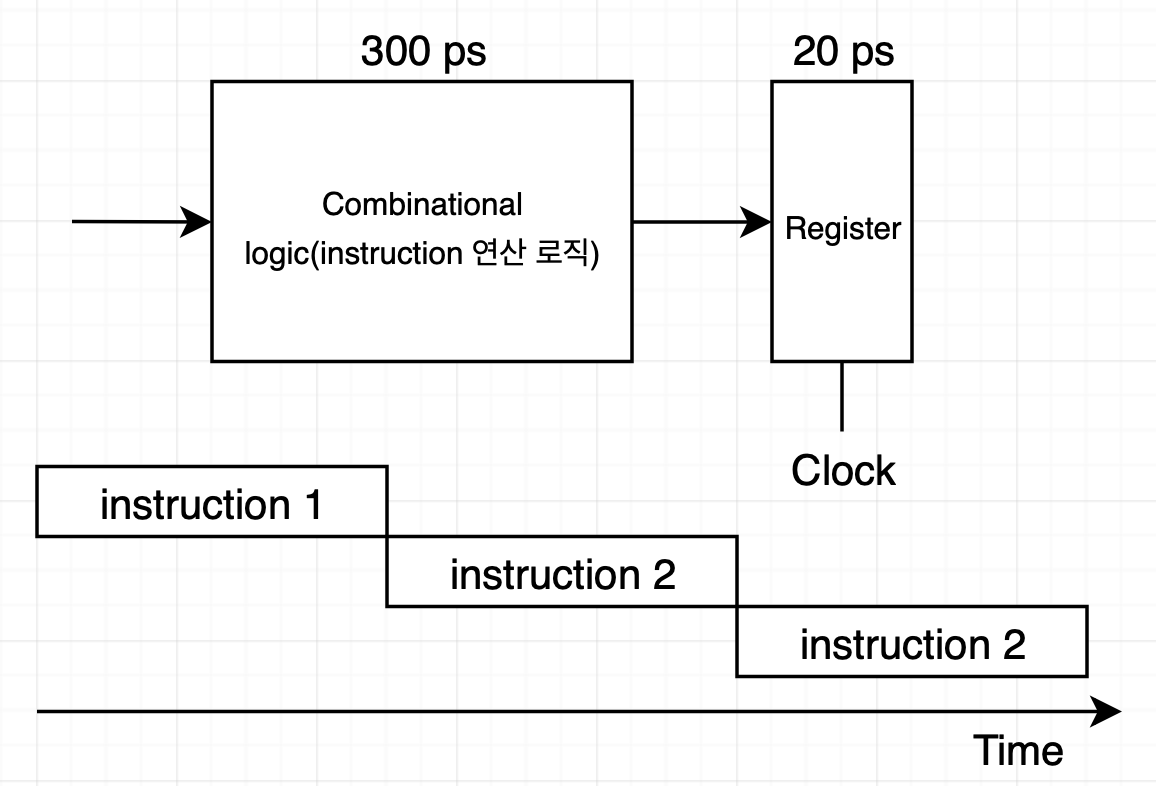 하나의 instruction을 시작부터 끝까지 실행하는 데 걸리는 시간을 delay라고 합니다. 위 그림에선 로직 수행에 300PS(PicoSecond)이 소요되고 register 로딩에 20PS가 소요되므로 총 delay는 300 + 20 = 320ps입니다. 이때 throughput(단위 시간당 처리하는 instruction의 양)은 다음과 같습니다.
Throughput = $1 instruction\over (20 + 300)ps$ * $1000ps\over 1ns$ = 3.12GOPS(giga-instructions per second)
만약 combinational logic 단계를 3단계로 나눌 수 있다면 intruction1이 두 번째 단계를 수행할 때 instruction2가 첫 번째 단계를 수행할 수 있습니다. 이 경우 3개의 클럭이 존재하며 그림으로 표현하면 다음과 같습니다.
하나의 instruction을 시작부터 끝까지 실행하는 데 걸리는 시간을 delay라고 합니다. 위 그림에선 로직 수행에 300PS(PicoSecond)이 소요되고 register 로딩에 20PS가 소요되므로 총 delay는 300 + 20 = 320ps입니다. 이때 throughput(단위 시간당 처리하는 instruction의 양)은 다음과 같습니다.
Throughput = $1 instruction\over (20 + 300)ps$ * $1000ps\over 1ns$ = 3.12GOPS(giga-instructions per second)
만약 combinational logic 단계를 3단계로 나눌 수 있다면 intruction1이 두 번째 단계를 수행할 때 instruction2가 첫 번째 단계를 수행할 수 있습니다. 이 경우 3개의 클럭이 존재하며 그림으로 표현하면 다음과 같습니다.
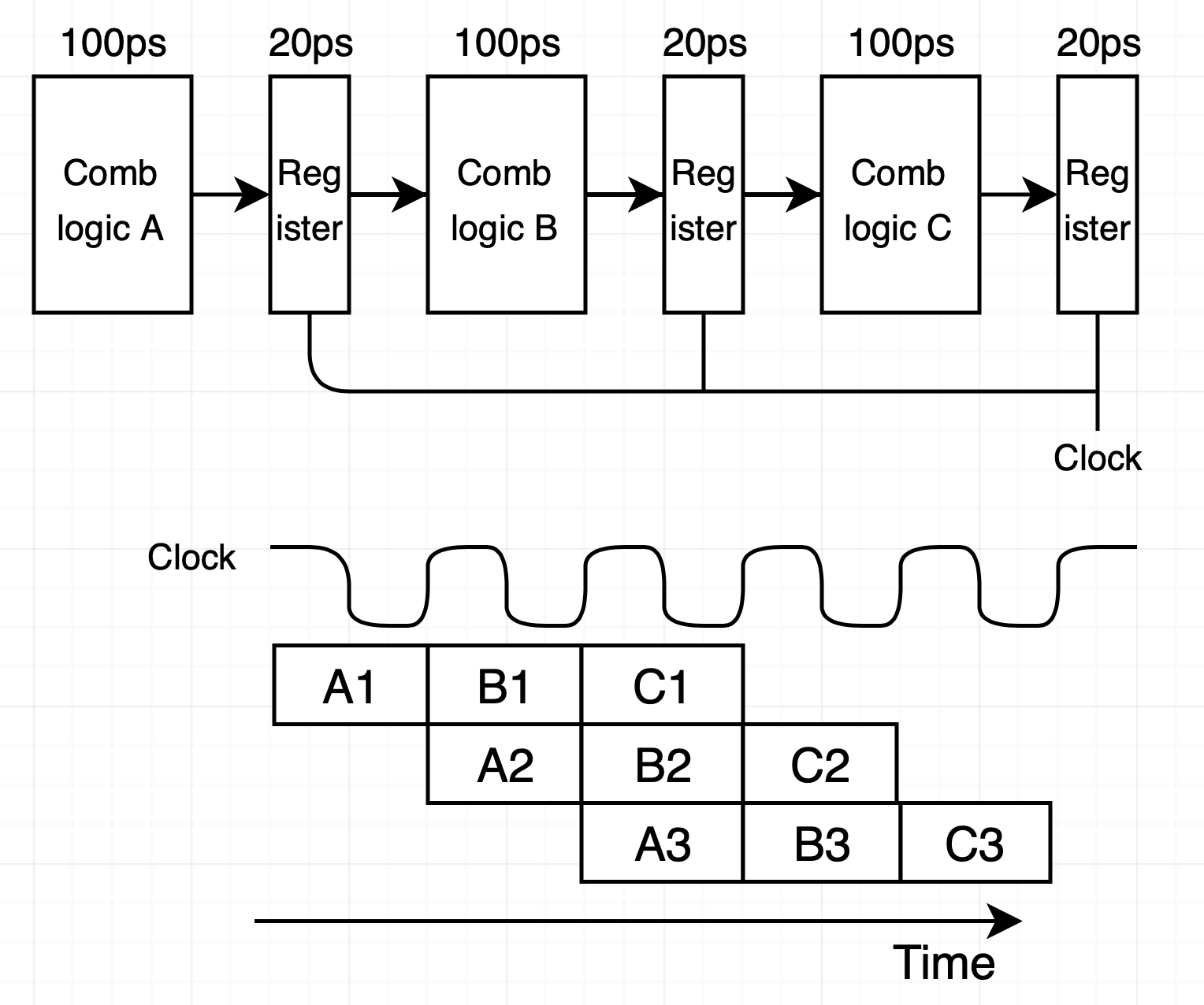 이 방식의 delay는 3 * (100 + 20) = 360ps입니다. 하나의 combinational logic으로 instruction 연산 수행을 하던 것에 비해 delay가 360/320 = 1.12배 증가했습니다. 반면 throughput은 $1 instruction\over (100 + 20)ps$ * $1000ps\over 1ns$ = 8.33GOPS(giga-instructions per second)으로 8.33/3.12 = 2.67배 개선되었습니다. 이처럼 파이프라인을 사용하면 delay를 다소 증가시키는 대신 throughput을 개선할 수 있습니다.
이 방식의 delay는 3 * (100 + 20) = 360ps입니다. 하나의 combinational logic으로 instruction 연산 수행을 하던 것에 비해 delay가 360/320 = 1.12배 증가했습니다. 반면 throughput은 $1 instruction\over (100 + 20)ps$ * $1000ps\over 1ns$ = 8.33GOPS(giga-instructions per second)으로 8.33/3.12 = 2.67배 개선되었습니다. 이처럼 파이프라인을 사용하면 delay를 다소 증가시키는 대신 throughput을 개선할 수 있습니다.
파이프라인 연산 과정
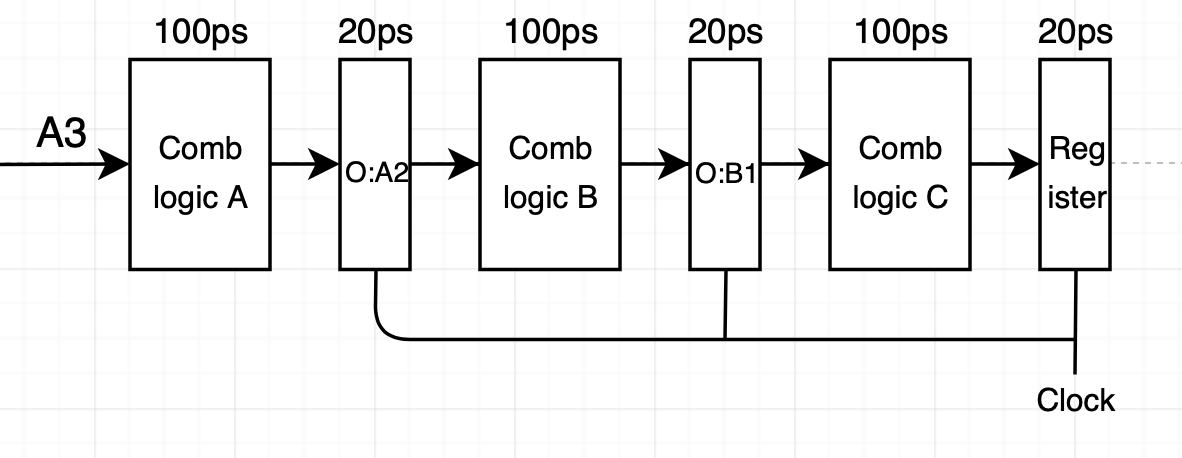
위 그림에서 볼 수 있듯이 파이프라인 각 단계들 간에 instruction 이동은 클럭 신호에 의해 제어됩니다. 클럭 주기는 120ps입니다. 파이프라인 연산 과정을 살펴보기 위해 위 그림에서 C1, B2, A3가 수행되는 부분을 상세히 살펴보겠습니다.
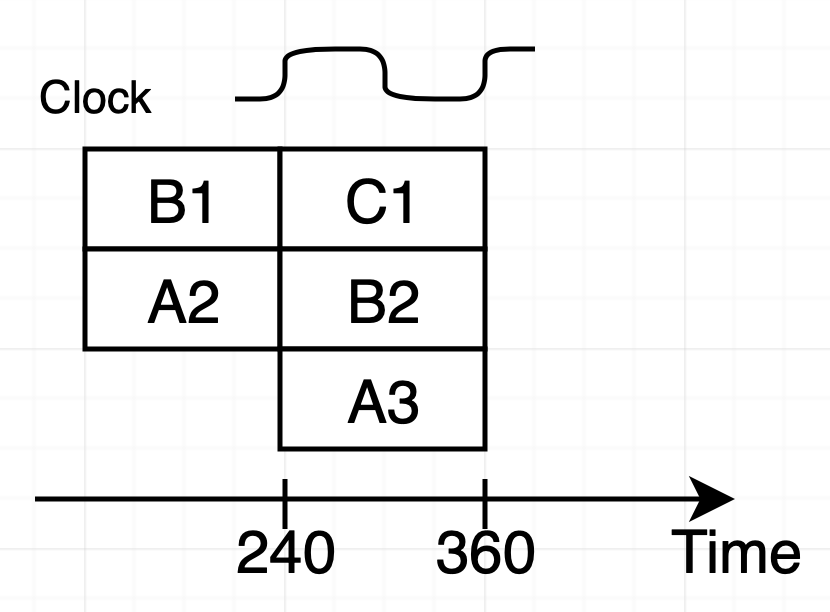 우선 240ps 직전입니다. 직전 클럭에서 수행된 instruction 단계들에 대한 값이 레지스터 입력으로 도착했지만 이전에 사용한 값이 여전히 레지스터에 출력으로 남아 있습니다.
우선 240ps 직전입니다. 직전 클럭에서 수행된 instruction 단계들에 대한 값이 레지스터 입력으로 도착했지만 이전에 사용한 값이 여전히 레지스터에 출력으로 남아 있습니다.
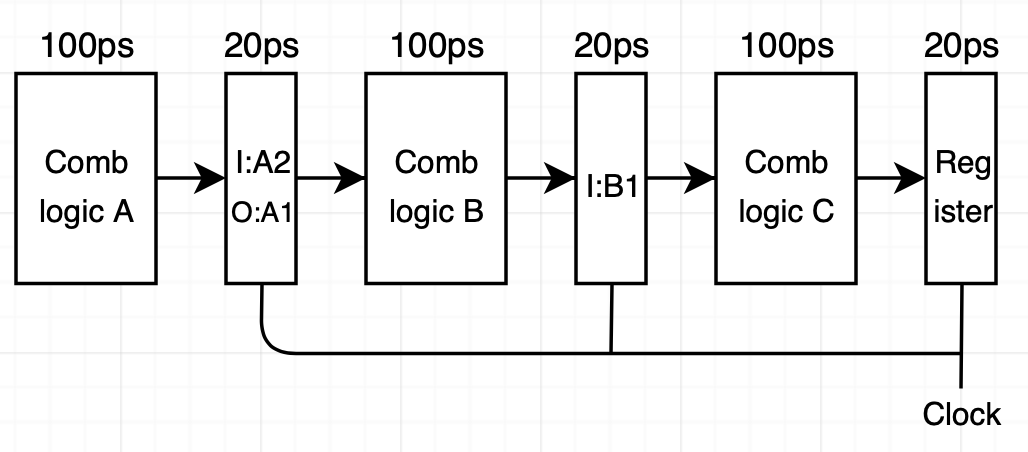 이제 240ps가 되고 클럭이 올라갑니다. 그러면 A2, B1 결과 입력들이 레지스터에 적제 되어 출력이 됩니다. A3는 계산을 시작하기 위해 설정됩니다.
이제 240ps가 되고 클럭이 올라갑니다. 그러면 A2, B1 결과 입력들이 레지스터에 적제 되어 출력이 됩니다. A3는 계산을 시작하기 위해 설정됩니다.
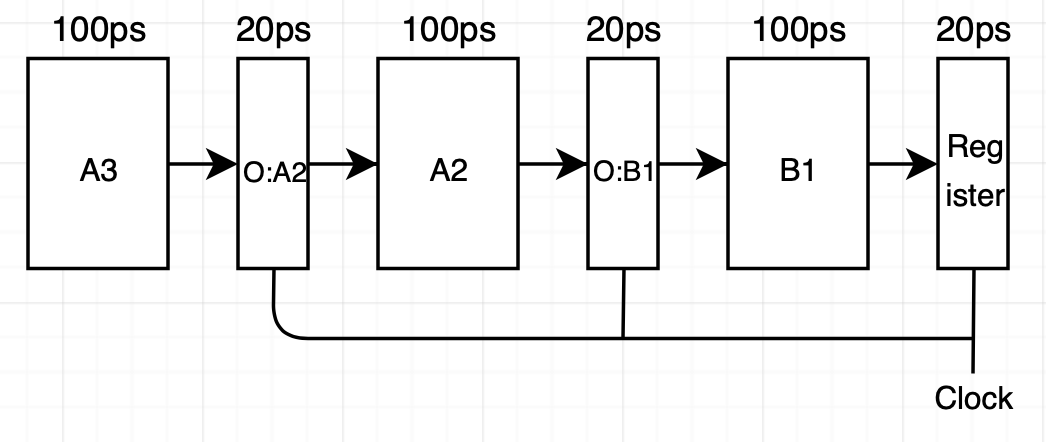
 신호들은 각자 단계에 맞는 조합 로직들을 통과합니다. 이때 각 신호들은 서로 다른 속도로 단계를 통과해 진행할 수 있습니다.
신호들은 각자 단계에 맞는 조합 로직들을 통과합니다. 이때 각 신호들은 서로 다른 속도로 단계를 통과해 진행할 수 있습니다.
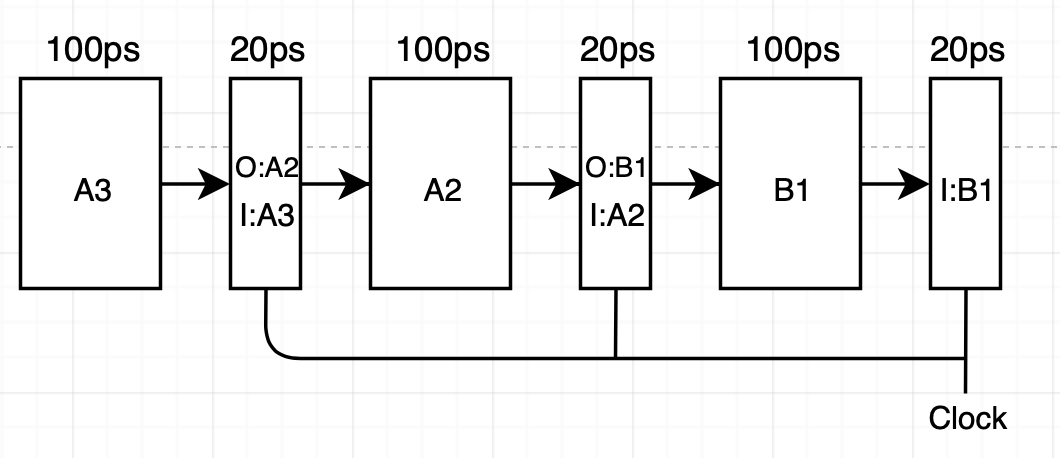
 마지막으로 360ps 직전에 각 단계의 결과는 파이프라인 레지스터의 입력에 도착합니다. 클럭이 360ps에서 상승하면 각 instruction들은 한 개의 파이프라인 단계를 통과해 위와 같은 과정을 다시 진행합니다.
마지막으로 360ps 직전에 각 단계의 결과는 파이프라인 레지스터의 입력에 도착합니다. 클럭이 360ps에서 상승하면 각 instruction들은 한 개의 파이프라인 단계를 통과해 위와 같은 과정을 다시 진행합니다.
 위 과정에서 각 신호들이 각 단계를 통과하는 속도가 다르다는 것에 주목해 보면 클럭을 낮추는 것이 파이프라인 동작에 영향을 주지 않는다는 것을 알 수 있습니다. 반면 클럭을 너무 빠르게 높이는 것은 다음 클럭이 상승할 때까지 값들이 조합 로직을 통과하지 못하게 할 수도 있기 때문에 위험합니다.
위 과정에서 각 신호들이 각 단계를 통과하는 속도가 다르다는 것에 주목해 보면 클럭을 낮추는 것이 파이프라인 동작에 영향을 주지 않는다는 것을 알 수 있습니다. 반면 클럭을 너무 빠르게 높이는 것은 다음 클럭이 상승할 때까지 값들이 조합 로직을 통과하지 못하게 할 수도 있기 때문에 위험합니다.
파이프라이닝의 한계
비균일 분리 (Nonuniform Paritioning)
이전 예제들에서 각 단계는 모두 균등한 실행 시간 동안 실행된다는 가정을 했습니다. 하지만, 이는 이상일뿐 실제 상황에선 각 단계마다 실행 시간이 차이 납니다. ALU나 메모리 같은 일부 하드웨어 유닛은 더 짧은 delay를 가진 유닛으로 분리할 수 없기 때문입니다. 이런 차이는 파이프라인 효과를 감소시키는 요인이며 이를 비균일 분리라 합니다.
비균일 분리 예제를 살펴보겠습니다.
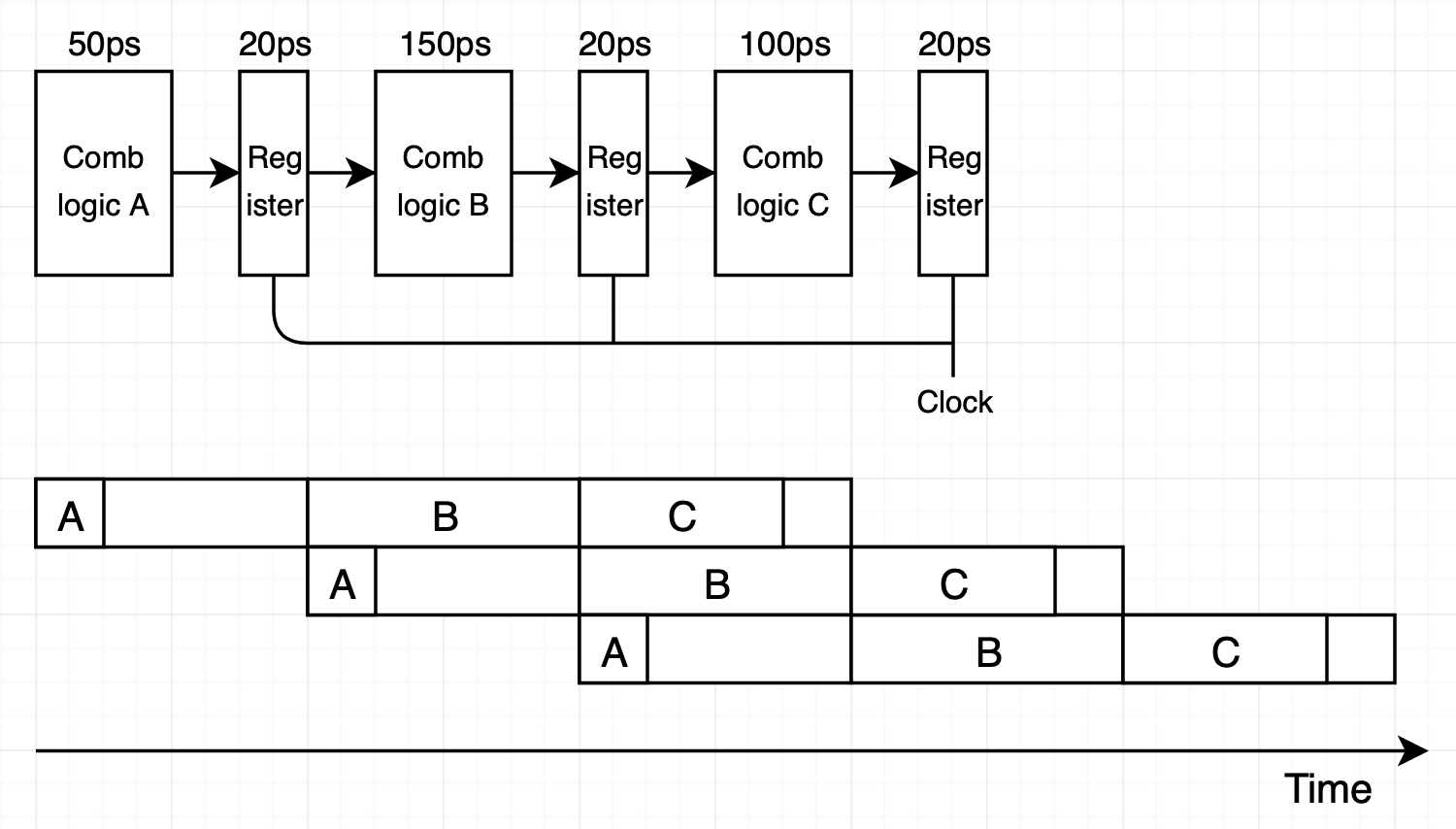 각 단계 조합 로직이 하나의 클럭 동안 온전히 연산을 수행하게 하기 위해선 가장 느린 단계의 delay를 클럭 사이클로 잡아야 합니다. 따라서 클럭 사이클은 Comb logic B로 인해 170ps가 되고 A 단계에서 100ps, C 단계에서 50ps 동안 idle이 발생합니다. Delay는 170*3=510ps가 되고 throughput은 $1 instruction\over 170 ps$ * $1000ps\over 1ns$ = 5.88GIPS가 됩니다.
각 단계 조합 로직이 하나의 클럭 동안 온전히 연산을 수행하게 하기 위해선 가장 느린 단계의 delay를 클럭 사이클로 잡아야 합니다. 따라서 클럭 사이클은 Comb logic B로 인해 170ps가 되고 A 단계에서 100ps, C 단계에서 50ps 동안 idle이 발생합니다. Delay는 170*3=510ps가 되고 throughput은 $1 instruction\over 170 ps$ * $1000ps\over 1ns$ = 5.88GIPS가 됩니다.
Buffering overhead
만약 파이프 라이닝 단계를 3개에서 6개로 올린다면 이론적으로 throughput은 2배 증가해야 합니다. 그러나 레지스터를 통과하는 지연시간으로 인해 실제로 증가하는 thorughput은 그보다 적습니다.
 이 예제에서 delay는 70ps이고 처리량은 14.29GIPS입니다. 따라서 throughput은 3-way-pipelining과 비교했을 때 2배 보다 적은 4.29/8.33=1.71배 좋아졌습니다. 이렇듯 파이프라인 단계 수를 늘리면 버퍼링 오버헤드가 커져서 어느 순간 thorughput이 꺽이게 됩니다.
부가적으로 최신 프로세스들은 프로세서의 클럭 속도를 최대치로 올리기 위해 많은 단계의 파이프라인을 사용합니다(홍보를 위해). 인텔 프로세스의 경우 보통 15단계 이상을 사용합니다.
이 예제에서 delay는 70ps이고 처리량은 14.29GIPS입니다. 따라서 throughput은 3-way-pipelining과 비교했을 때 2배 보다 적은 4.29/8.33=1.71배 좋아졌습니다. 이렇듯 파이프라인 단계 수를 늘리면 버퍼링 오버헤드가 커져서 어느 순간 thorughput이 꺽이게 됩니다.
부가적으로 최신 프로세스들은 프로세서의 클럭 속도를 최대치로 올리기 위해 많은 단계의 파이프라인을 사용합니다(홍보를 위해). 인텔 프로세스의 경우 보통 15단계 이상을 사용합니다.
Pipeline hazard
데이터 의존성
기계어 프로그램을 실행하는 시스템에서는 연속적인 일부 instruction들이 서로 잠재적인 의존성을 가지는 경우가 있습니다.
1
2
3
1 irmovq $50, %rax // 50을 레지스터 %rax에 저장
2 addq %rax, %rbx // 레지스터 %rbx의 값과 %rax의 값을 더해%rbx에 저장
3 mrmovq 100(%rbx), %rdx // 메모리 (%rbx주소값+100)에 위치한 데이터를 레지스터 %rdx에 저장
위 예시의 경우 1번 줄의 %rax와 2번 줄의 %rax가, 2번줄의 %rbx와 3번 줄의 %rbx가 서로 의존성을 갖습니다. 이는 결국 instruction의 결과를 다음 instruction의 입력으로 사용한다는 의미이므로 다음과 같은 설계를 고려해 볼 수 있습니다.
 그러나 파이프라이닝을 사용하면 instruction 하나가 완료되기 전에 다른 instruction이 이전 단계에 진입하므로 첫 번째 instruction의 결과를 4번째 instruction이 받게 됩니다.
그러나 파이프라이닝을 사용하면 instruction 하나가 완료되기 전에 다른 instruction이 이전 단계에 진입하므로 첫 번째 instruction의 결과를 4번째 instruction이 받게 됩니다.
 따라서 데이터 의존성이 존재하더라도 파이프라이닝이 올바른 동장을 하게 하기 위한 방법이 필요합니다. 이를 위해 우선 의존성 유형에 대해 알아보겠습니다.
따라서 데이터 의존성이 존재하더라도 파이프라이닝이 올바른 동장을 하게 하기 위한 방법이 필요합니다. 이를 위해 우선 의존성 유형에 대해 알아보겠습니다.
의존성과 hazard
의존성은 다음과 같은 두 가지 형태가 있습니다.
- 데이터 의존성: 한 개의 instruction이 계산한 결과가 다음에 오는 instruction을 위한 데이터로 사용되는 경우
- 제어 의존성: jump, call, ret와 같이 한 개의 instruction이 다음에 따라오는 instruction의 위치를 결정하는 경우 이런 의존성들이 파이프라인으로 인해 잘못된 계산을 야기할 가능성이 있는 것을 hazard라 합니다. Hazrd 역시 data hazard와 control hazard로 나뉩니다. Data harad와 control hazard에 대해 더 알아보기 전에 이제부터 사용할 파이프라이닝 예시에 대해 간단히 설명하겠습니다. 아래 예시에서 파이프라인의 단계는 총 5단계로 이뤄지며 각 단계는 다음과 같은 동작을 합니다.
- Fetch: 명령어를 instruction memory에서 읽어온다. F로 표기
- Decode: 명령어를 해독한다. Register file에서 oprande 값을 읽어온다. D로 표기
- Execute: 명령어를 실행해 연산 결과값 또는 메모리 주소값을 계산한다. E로 표기
- Memory: Data memory에서 값을 read/write. M으로 표기
- Write back: register file에 실행 결과값을 저장한다.
stall을 사용한 data hazard 회피
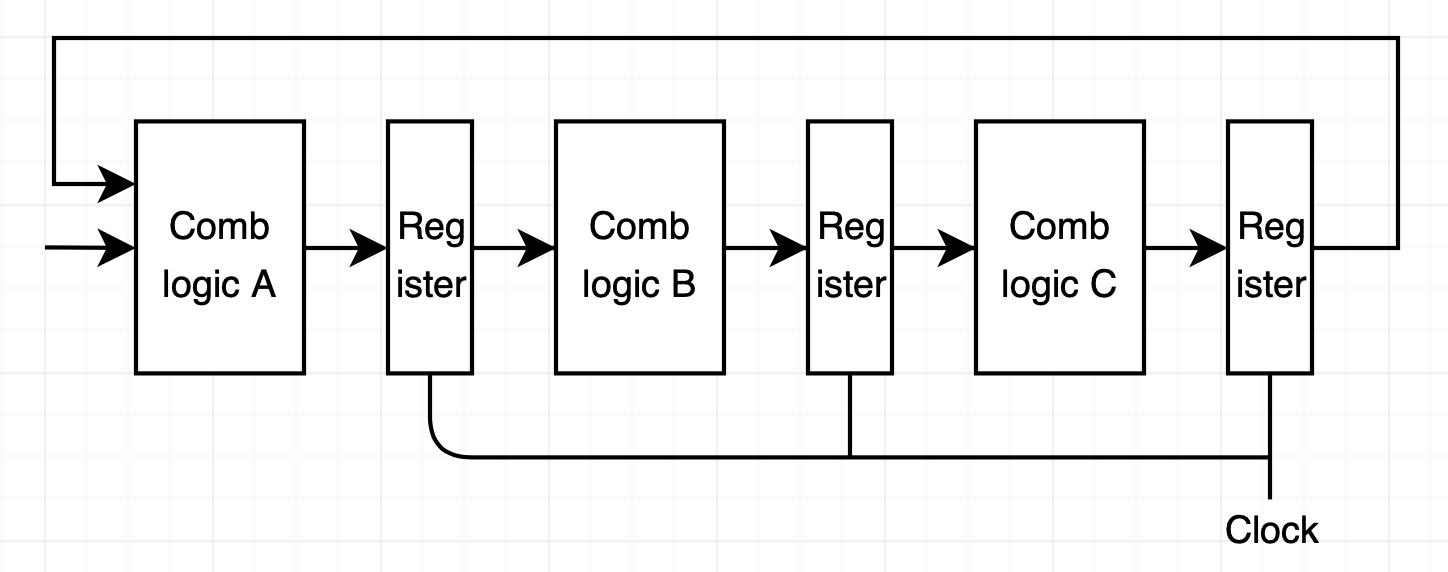
우선 data hazard가 발생하는 예시를 살펴보겠습니다.
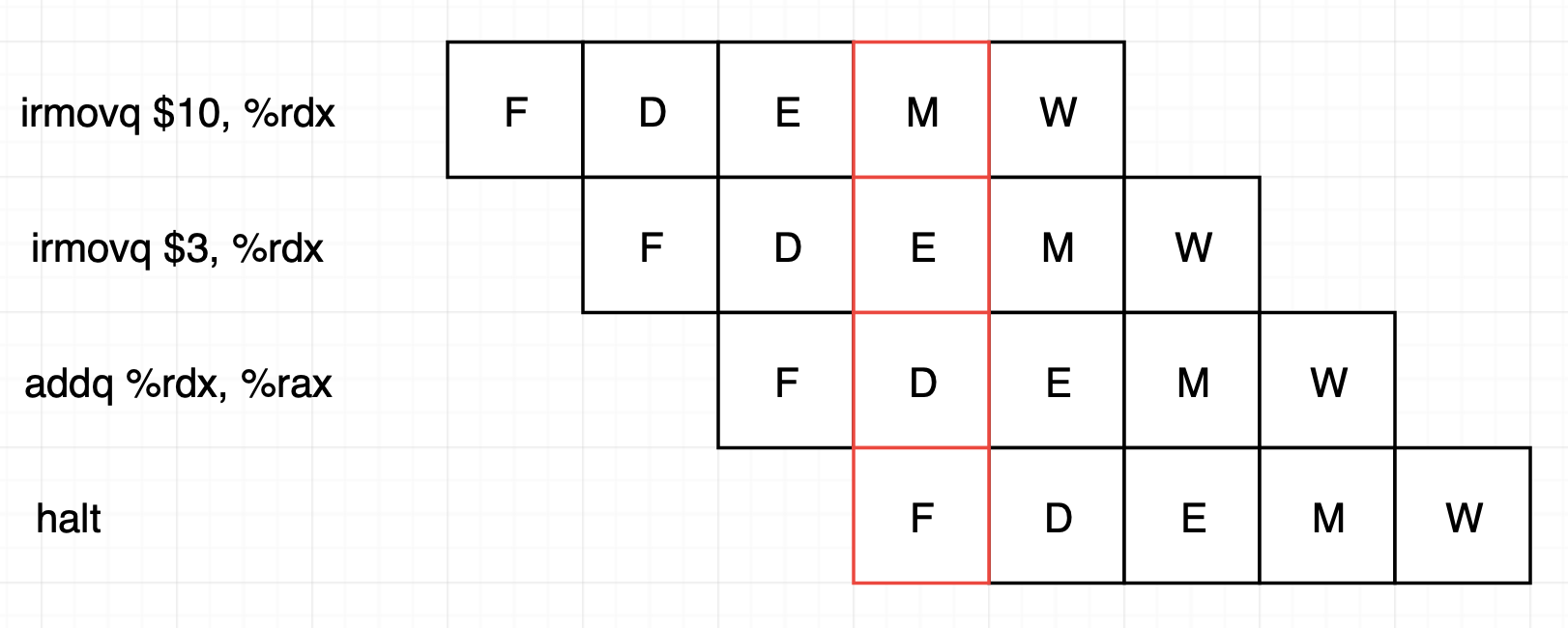 이 예시에선 빨간색 부분에서 data hazard가 발생합니다. 첫 번째 instruction은 memory 단계로 아직 메모리에 값을 쓰는 것을 완료하지 않았습니다. 두 번째 instruction은 새로운 값 연산을 실행 중입니다. 그러나 3번째 instruction은 1, 2번째 instruction 결과를 활용하고 있어서 틀린 값이 나옵니다.
Stalling은 한 그룹의 instruction들을 현재 단계에 붙잡아두고, 나머지 instruction들은 계속 남은 단계를 지속하게 하는 방법입니다. 필요한 instruction들을 현재 단계에 붙잡아두기 위해 버블을 삽입합니다. 버블은 동적으로 생성된 nop(아무것도 하지 않는 instruction) instruction과 비슷합니다.
Data hazard 예시를 stall을 이용해 해결하면 다음과 같은 모습을 가집니다.
이 예시에선 빨간색 부분에서 data hazard가 발생합니다. 첫 번째 instruction은 memory 단계로 아직 메모리에 값을 쓰는 것을 완료하지 않았습니다. 두 번째 instruction은 새로운 값 연산을 실행 중입니다. 그러나 3번째 instruction은 1, 2번째 instruction 결과를 활용하고 있어서 틀린 값이 나옵니다.
Stalling은 한 그룹의 instruction들을 현재 단계에 붙잡아두고, 나머지 instruction들은 계속 남은 단계를 지속하게 하는 방법입니다. 필요한 instruction들을 현재 단계에 붙잡아두기 위해 버블을 삽입합니다. 버블은 동적으로 생성된 nop(아무것도 하지 않는 instruction) instruction과 비슷합니다.
Data hazard 예시를 stall을 이용해 해결하면 다음과 같은 모습을 가집니다.
 Stall 구현은 매우 간단하지만 성능이 좋지 않습니다. Instruction 한 개에서 레지스터를 갱신하고 바로 따라오는 instruction이 해당 레지스터를 사용하는 경우가 많습니다. 이때마다 최대 3개의 사이클을 stall해야 하기 때문에 전체 처리량을 상당히 감소시킵니다.
Stall 구현은 매우 간단하지만 성능이 좋지 않습니다. Instruction 한 개에서 레지스터를 갱신하고 바로 따라오는 instruction이 해당 레지스터를 사용하는 경우가 많습니다. 이때마다 최대 3개의 사이클을 stall해야 하기 때문에 전체 처리량을 상당히 감소시킵니다.Forwarding을 이용한 data hazard 회피
Decode 단계는 레지스터 파일에서 source operand를 읽어옵니다. 레지스터 파일에 있어야 하는 값은 memory 또는 write back 단계에서 source register 값을 이용해 쓰기를 합니다. 따라서 쓰기가 완료될 때까지 대기하지 않고 decode 단계에서 필요한 값을 source register에서 바로 읽어올 수 있습니다.
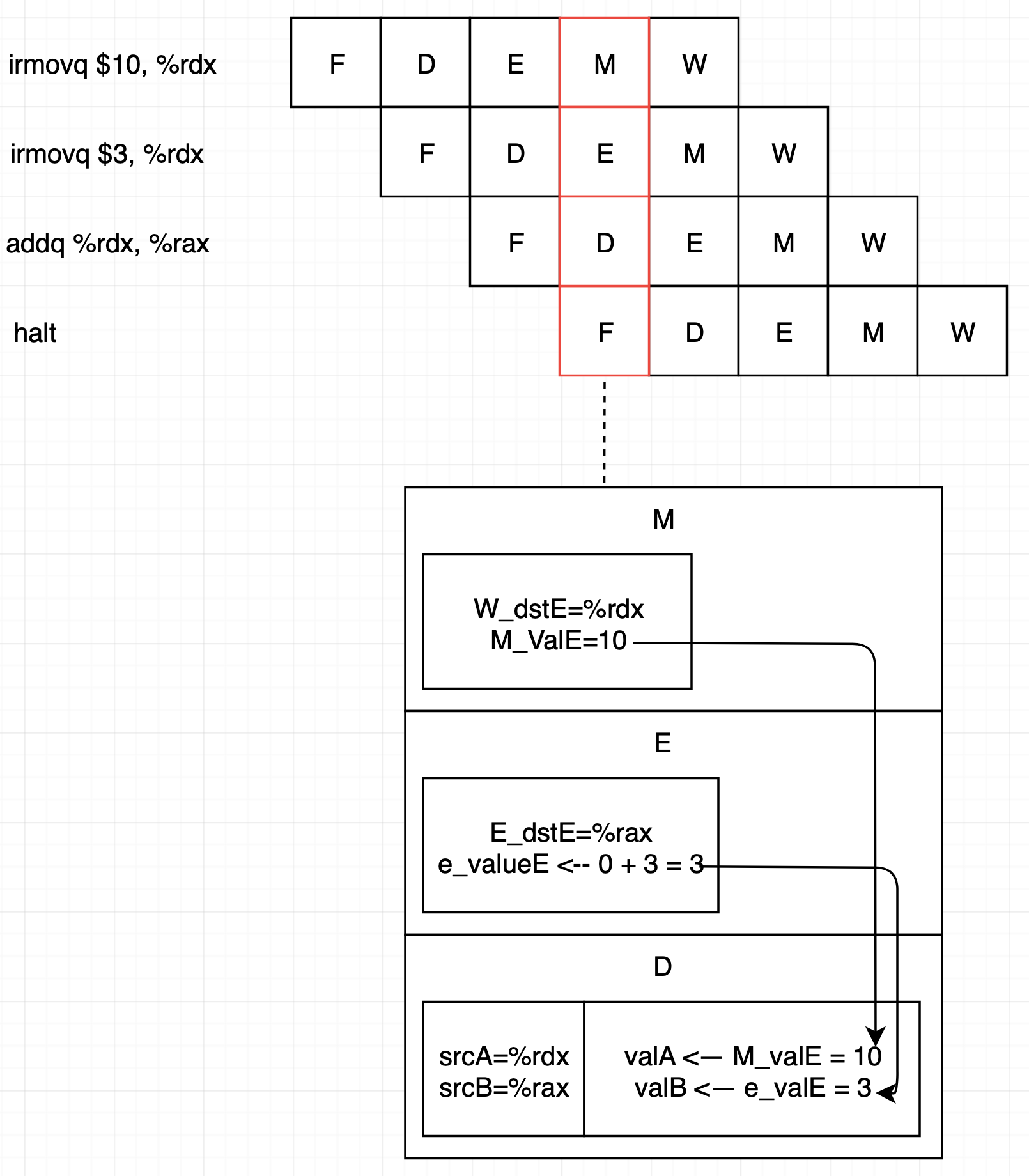 이 예제에서는 ALU가 만든 값을 forwarding 하고 있으며 Memory 단계와 Execute 단계의 쓰기포트 E와 관련있습니다. 이 값 뿐만 아니라 메모리에서 읽은 값, 쓰기 포트 M으로 가는 값도 forwarding에 사용할 수 있습니다. Forwarding 목적지는 valA, valB 두 개입니다(ALU operand).
이 예제에서는 ALU가 만든 값을 forwarding 하고 있으며 Memory 단계와 Execute 단계의 쓰기포트 E와 관련있습니다. 이 값 뿐만 아니라 메모리에서 읽은 값, 쓰기 포트 M으로 가는 값도 forwarding에 사용할 수 있습니다. Forwarding 목적지는 valA, valB 두 개입니다(ALU operand).Load/Use data hazard
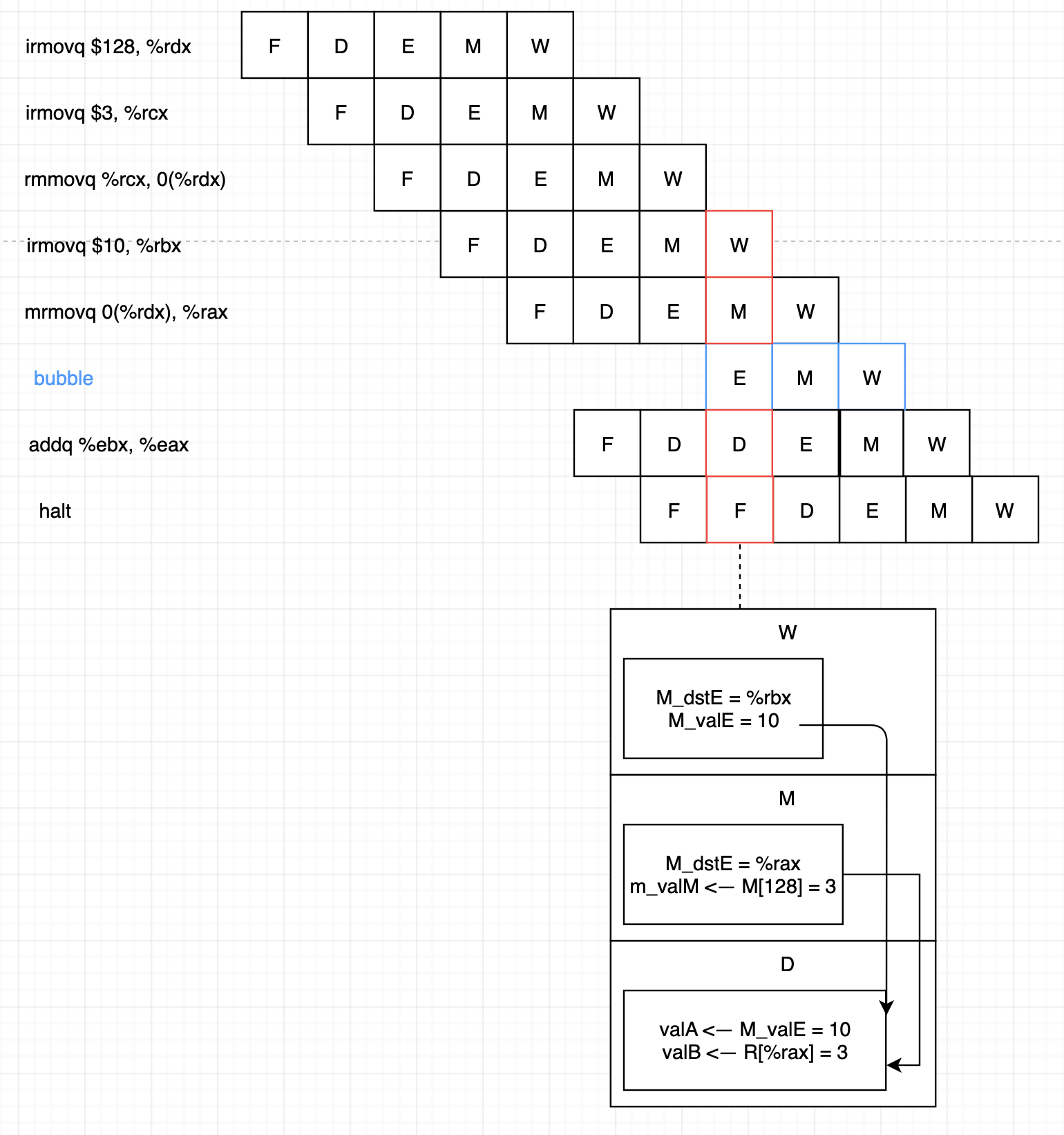
메모리 읽기가 파이프라인 뒷부분에서 발생한다면 forwarding만으로는 data hazard를 처리할 수 없습니다.
 위 예시에선 addq %ebx, %eax의 decode 단계에서 사용해야 하는 값이 그다음 사이클의 mrmovq 0(%rdx), %rax의 memory 단계에서 연산되고 있습니다. 이렇게 필요한 값이 계산되는 단계 자체가 역순이 된 경우를 load/use data hazard라고 하며 이는 forward와 stall을 모두 사용해야 해결할 수 있습니다. 이와 같이 load/use hazard를 해결하기 위해 stall을 사용하는 것을 load interlock이라 합니다. forwarding과 stall을 같이 사용한 형태는 data hazard를 대부분 처리할 수 있습니다.
위 예시에선 addq %ebx, %eax의 decode 단계에서 사용해야 하는 값이 그다음 사이클의 mrmovq 0(%rdx), %rax의 memory 단계에서 연산되고 있습니다. 이렇게 필요한 값이 계산되는 단계 자체가 역순이 된 경우를 load/use data hazard라고 하며 이는 forward와 stall을 모두 사용해야 해결할 수 있습니다. 이와 같이 load/use hazard를 해결하기 위해 stall을 사용하는 것을 load interlock이라 합니다. forwarding과 stall을 같이 사용한 형태는 data hazard를 대부분 처리할 수 있습니다.
Control hazard 회피
Control hazard는 data hazard에 비해 발생하는 경우가 더 적습니다. Control hazard는 프로세서가 이전 단계들에서 현재 instruction에 기초해 다음 instruction의 주소를 올바르게 결정할 수 없을 때 발생합니다. 따라서 오직 ret와 jump instruction 등 제어 명령에 한해서 발생합니다. Control hazard 예시를 살펴보겠습니다.
1 2 3 4 5 6 7 8 9 10
0x000: irmovq stack, %rsp # Initialize stack pointer 0x00a: call proc # Procedure call 0x013: irmovq $10, %rdx # Return point 0x01d: halt 0x020: .pos 0x20 0x020: proc: # proc: 0x020: ret # Return immediately 0x021: rrmovq %rdx, %rbx # Not executed 0x030: .pox 0,30 0x030: stack: # stack: Stack pointer
이 예시에선 call을 이용해 proc 부분을 실행하고 0x020에서 ret를 수행해 다시 0x013부터 instruction을 실행합니다. 따라서 실질적인 실행 순서는 다음과 같습니다.
1 2 3 4 5 6
0x000: irmovq stack, %rsp # Initialize stack pointer 0x00a: call proc # Procedure call 0x020: proc: # proc: 0x020: ret # Return immediately 0x013: irmovq $10, %rdx # Return point ...
이 때 ret는 write back 단계가 되어서야 stack pointer 주소를 업데이트 해서 0x013에 진입할 수 있기 때문에 다음과 같이 bubble을 삽입해야 합니다.
