이 글을 읽기 전 TCP 송수신 과정에 대해 알고 있어야 합니다. TCP 송수신 과정에 대해 잘 알지 못한다면 다음 글을 우선 읽는 것을 추천합니다.
Chapter 2 story 3. 데이터 송/수신한다.
Flow control
TCP 커넥션이 성사되면 송수신 측은 각자의 수신 버퍼를 가지게 됩니다. TCP 커넥션을 통해 올바른 데이터를 순서대로 받으면, 이 데이터를 각지의 수신 버퍼에 저장합니다. 그러면 애플리케이션 프로세스가 이 버퍼에 접근해 데이터를 읽습니다. 이때, 만약 애플리케이션 프로세스가 다른 태스크 진행 때문에 수신 버퍼가 다 찰 때까지 버퍼에 있는 데이터를 읽지 못한다면 버퍼 오버플로우가 발생하게 됩니다. 이런 일을 방지하기 위해 TCP는 flow control이라는 기능을 제공합니다.
flow control은 송신측이 패킷을 보내는 속도를 수신 측 애플리케이션이 수신 측 버퍼에서 데이터를 읽는 속도에 따라 조절하는 것을 의미합니다. 즉, flow control은 송신 측과 수신 측 간의 데이터 처리 속도에 관한 제어입니다.
TCP는 flow control을 위해 송신측에서 receive window라는 TCP 패킷 헤더를 사용합니다. 이는 송신 측에게 수신 측 버퍼가 얼마큼의 여유공간이 있는지를 알리는 용도로 사용합니다. receiver window를 어떻게 사용하는지 알기 위해 호스트 A가 호스트 B에게 TCP 커넥션을 통해 대용량 파일을 전송한다고 가정하겠습니다. 호스트 B가 가지는 버퍼 크기를 RcvBuffer, 호스트 B 측 애플리케이션이 읽은 마지막 바이트를 LastByteRead, 호스트 B 측이 버퍼에 저장한 데이터의 마지막 바이트를 LastByteRecvd라 하겠습니다.
TCP는 버퍼 오버플로우를 허용하지 않으므로 LastByteRcvd - LastByteRead <= RcvBuffer여야 합니다. receive window를 rwnd라 하면, rwnd = RcvBuffer - [LastByteRcvd - LastByteRead]가 됩니다. 버퍼의 빈 공간은 애플리케이션이 버퍼를 읽음에 따라 동적으로 변하기 때문에 rwnd값도 동적으로 변합니다.
호스트 B는 rwnd 값을 receive window 필드에 넣고 호스트 A에게 패킷을 전송해 버퍼가 얼마나 비어있는지 알립니다. 호스트 A는 flow control을 위해 마지막으로 자신이 보낸 패킷이 담고 있는 마지막 바이트 위치(이를 LastByteSent라 하겠습니다)와 송신측이 마지막으로 ACK 한 바이트 위치(이를 LastByteAcked라 하겠습니다)를 알고 있어야 합니다. LastByteSent - LastByteAcked를 해서 ACK를 하지 않은 데이터를 파악하고, 이 값이 rwnd보다 작게 유지해야 합니다(LastByteSent - LastByteAcked <= rwnd). 그래야 오버플로우를 방지할 수 있습니다.
receiver window를 활용한 flow control은 약간의 문제가 있습니다. 호스트 B의 버퍼가 가득 차서 rwnd값을 0으로 지정하고 응답을 보냈을때, A가 B에게 더 이상 보낼 패킷이 남아있지 않다고 가정해 보겠습니다. 이 상황에서 호스트 B의 애플리케이션 프로세스가 버퍼를 읽어 버퍼에 여유 공간이 생기더라도 호스트 B는 버퍼에 공간이 있음을 호스트 A에게 알리지 않습니다. TCP에서는 보내야 할 데이터가 있거나 ACK를 응답해야 할 때만 패킷을 보내기 때문입니다. 따라서 이 문제를 해결하기 위해 수신 측이 받은 rwnd 값이 0이라면 수신 측은 1바이트 크기의 패킷을 지속적으로 보냅니다. 만약 수신 측의 버퍼가 빈다면 응답의 receive window 값이 0이 아닌 패킷을 받으므로 다시 패킷을 전송할 수 있습니다.
Congestion Control
reliable data transfer service에서 패킷 손실이 발생한다는 것은 네트워크가 혼잡해짐에 따라 라우터 버퍼에서 오버플로우가 발생했을 확률이 크다는 것을 의미합니다. 따라서 네트워크 congestion을 조절해 패킷 손실을 최소화해야 합니다. congestion을 조절하는 방법에는 여러가지가 있습니다. 이 방법들을 살펴보기 전에 우선 호스트가의 전송률(tansmission rate) 증가에 따라 congestion이 어떻게 발생하는지를 여러 시나리오에 거쳐서 확인해 보겠습니다.
Congestion은 어떻게 발생하는가
시나리오1: Two senders, a Router with Infinite Buffers
가장 간단한 경우입니다. 두 개의 호스트가 존재하고, 두 호스트 사이에 하나의 hop이 존재하는 경우입니다. 버퍼 크기 또한 무한합니다.
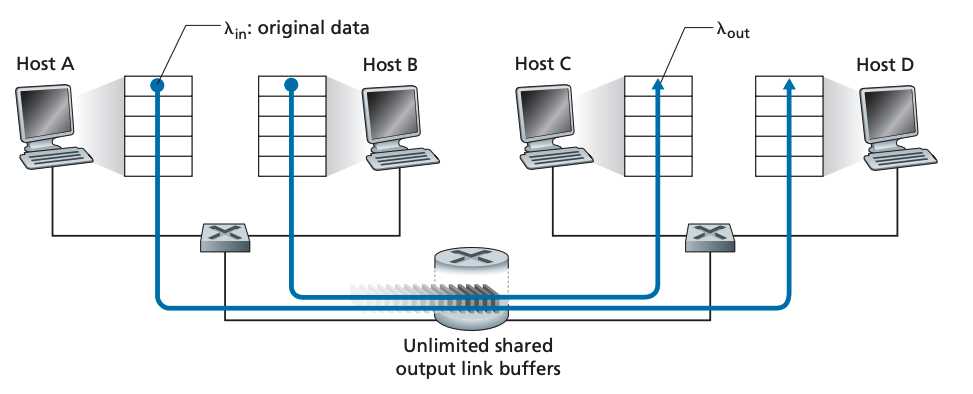
호스트 A, B가 평균 λin bytes/sec rate로 데이터를 송신한다고 가정해 봅시다. 이 시나리오에선 transport layer protocol이 단순히 메시지를 패킷으로 포장하고 송신하는 기능만 합니다. 호스트 A, B가 보낸 패킷은 R만큼의 밴드폭을 가진 라우터를 통과합니다. 이 라우터에는 내보내야 하는 패킷 양이 밴드폭을 초과할 때를 대비해 버퍼가 존재합니다. 위 그림에는 두 개의 커넥션이 존재합니다. 하나의 커넥션에 대한 congestion scenario를 살펴보면 다음과 같은 그래프가 나옵니다.
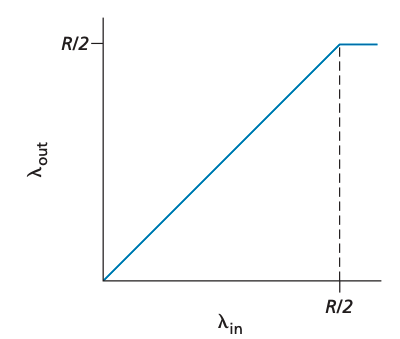
커넥션당 수율이 R/2에 근접한다는 것은 밴드폭을 잘 활용하고 있다는 뜻이므로 좋게 받아들여집니다. 그러나 지연시간은 수율이 링크 밴드폭에 가까워질수록 증가합니다. 전송률이 R/2를 넘어서면 라우터의 큐에서 대기하고 있는 패킷 개수는 무한해지며 송신 측과 수신 측 사이의 평균 대기 시간도 무한해집니다.
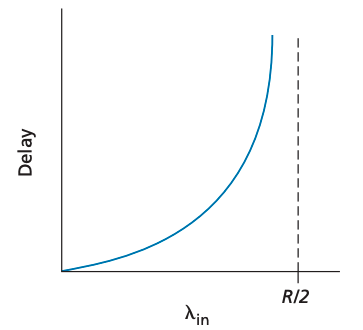
따라서 밴드폭을 다 채우는 것이 수율 관점에선 이상적이지만 지연 관점에선 이상적이지 않습니다. 따라서 패킷 도착률이 밴드폭에 가까워짐에 따라 대량의 queing delay가 발생합니다.
시나리오2: Two Senders and a Router with Finit Buffers
시나리오1의 가정을 조금만 바꿔봅시다. 이제 라우터의 버퍼는 유한한 크기를 가집니다. 따라서 버퍼가 다 차면 패킷 손실이 발생합니다. 둘째로, 각 커넥션은 reliable 하다고 가정합니다. 패킷 손실이 발생하면 송신 측은 해당 패킷을 재전송합니다. 애플리케이션이 소켓으로 보내는 original data 양을 λin bytes/sec라 하겠습니다. transport layer에서 보대는 세그먼트(original data + restransmitted data) 양을 λ'in bytes/sec라 하겠습니다.
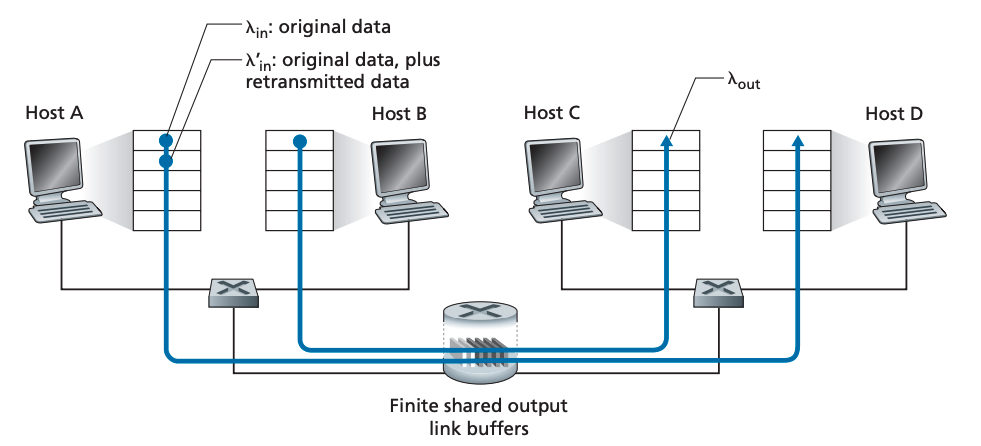
이번 시나리오의 퍼포먼스는 재전송이 어떤식으로 발생하느냐에 따라 달라집니다. 만약 호스트 A가 라우터 버퍼가 비어있는지를 확인할 수 있어서 버퍼가 비어있을 때에만 패킷을 송신한다고 하면 손실이 발생하지 않습니다. 따라서 λin == λ'in이며 수율은 λ'in과 같습니다. 이를 그래프로 표현하면 다음과 같습니다.
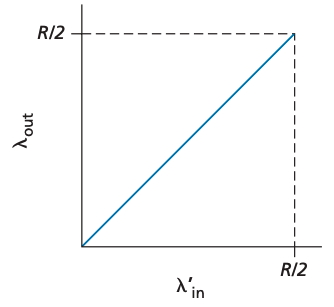
수율 관점에서 이 시나리오는 사용 가능한 밴드폭을 모두 사용하기에 이상적입니다. 이 시나리오에서 패킷 손실은 발생하지 않는다 가정하기 때문에 송신율은 R/2를 넘을 수 없습니다. 실제 상황에서 송신 측은 라우터 버퍼 상태를 파악할 수 없기 때문에 이 가정은 비현실적입니다.
이제 조금 더 현실적인 가정을 해봅시다. 송신측은 패킷 손실이 발생했을 때만 재전송을 한다는 가정을 해봅시다. 이때 λ'in(original data + retransmission data) == R/2라고 생각하면, 그래프는 다음과 같을 것입니다.

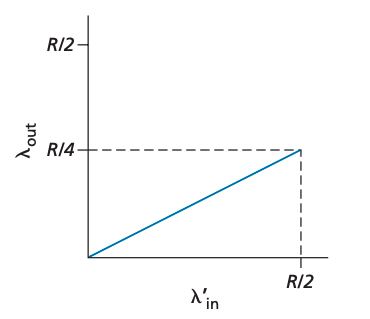
데이터가 수신측에 도달하는 양은 R/3입니다. 따라서 전체 R/2 중에 0.333R bytes/sec에 해당하는 데이터는 애플리케이션에서 전송한 original data이고 0.166R bytes/sec에 해당하는 데이터는 재전송된 데이터입니다. 이를 통해 수신 측이 손실된 패킷을 상쇄하기 위해 재전송하는 패킷은 버퍼 오버플로우의 한 원인임을 알 수 있습니다.
한가지 가정을 더 해보겠습니다. 패킷이 큐에 쌓여 지연이 발생한 상황에서 송신 측이 타임아웃을 내고 해당 패킷을 재전송하는 경우를 보겠습니다. 이 경우 original data packet과 재전송된 데이터 패킷 모두 수신 측에 전달되고 재전송된 데이터 패킷은 무시됩니다. 따라서 라우터는 필요 없는 재전송 패킷을 중계하기 위해 리소스를 낭비한 꼴이 됩니다. 이는 밴드폭 낭비와 직결됩니다. 아래 그래프는 모든 패킷이 두 번씩 중복 전송됐을 때의 상황을 나타냅니다.
시나리오 3: Four Senders, Routers with Finit Buffers, and Multihop paths
마지막으로 호스트 4개가 각각 홉을 두 개씩 통과하는 시나리오를 생각해 보겠습니다. 각 호스트는 reliable data transfer service를 위해 타임아웃과 재전송 메커니즘을 사용합니다. 모든 호스트는 original data 양이 λin bytes/sec이고 각 라우터 링크의 밴드폭은 R bytes/sec입니다.
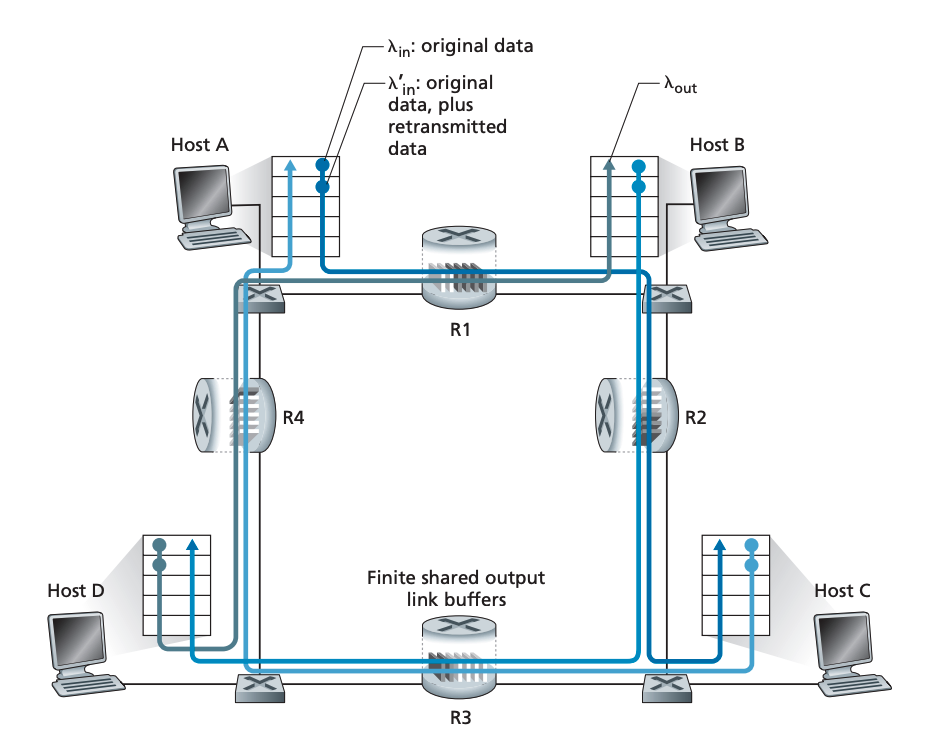
호스트 A와 호스트 C 커넥션을 살펴보겠습니다. 이 커넥션은 R1을 호스트 D - 호스트 B (D-B) 커넥션과 공유합니다. R2는 호스트 B - 호스트 D(B-D) 커넥션과 공유합니다. 이 상황에서 λin이 작다면 오버플로우가 발생할 확률이 극히 낮으므로, λin이 낮다면 약간의 λin 증가는 λout의 증가로 직결됩니다.
이제 λin가 매우 큰 상황을 상상해 보겠습니다. A-C 트래픽이 R1을 거쳐 R2에 도착하는 도착률은 최대 R입니다. 이 때, λ'in가 모든 커넥션에서 큰 값을 가진다면 R2에서의 B-D 트래픽은 A-C 트래픽보다 커질 수 있습니다. R2의 버퍼 사이즈는 한정적이기에 B-D 커넥션과 A-C 커넥션은 버퍼 사이즈를 가지고 서로 경쟁할 수밖에 없습니다. 따라서 B-D 커넥션 트래픽이 늘어난다면 A-C 트래픽은 줄어듭니다. 이 극한에선 부하가 무한으로 갈수록 R2 버퍼는 즉시 B-D 패킷으로 채워집니다. 그에 반해 R2에서의 A-C 수율은 0에 수렴합니다. 결국 A-C의 end-to-end 수율도 0에 수렴합니다. 따라서 부하 증가와 수율의 관계는 다음과 같습니다.

이 시나리오에선 두 번째 홉 라우터에서 패킷이 버려지기에 첫 번째 홉 라우터에서 두 번째 라우터로 패킷을 보내기 위해 상요한 리소스는 결국 낭비임을 알 수 있습니다. 따라서 패킷 전송 중 하나의 홉에서 패킷 손실이 발생한다면 패킷이 거쳤던 이전의 홉들에 대한 밴드폭이 모두 낭비돼서 결국엔 전체 밴드폭을 낭비한다는 것을 알 수 있습니다.
TCP Congestion Control
TCP는 end-to-end congestion control을 사용합니다. end-to-end congestion control에서는 네트워크 레이어는 아무런 역할도 하지 않습니다. 이는 IP가 network congestion에 관한 어떠한 피드백도 엔드시스템에게 제공하지 않기 때문입니다.
Classic TCP Conegestion Control
TCP는 Congestion을 제어하기 위해 각 송신 측이 송신하는 트래픽양을 제한합니다. 만약 TCP 송신측이 혼잡도에 따라 송신율을 조절합니다. 이 방식에 대해 다음과 같은 질문을 할 수 있습니다.
1. TCP 송신 측은 어떻게 송신율을 제한하나?
2. TCP 송신측은 어떻게 혼잡이 존재하는 것을 알 수 있나?
3. 어떤 알고리즘을 이용해 송신율을 조절해야 하나?
1번 질문에 대한 해결방식부터 살펴보겠습니다. 이전에 설명했듯이 TCP 커넥션의 각 엔드포인트에는 송/수신 버퍼와 여러 변수(LastByteRead, rwnd 등)들이 존재합니다. 송신 측은 TCP Congestion-Control 메커니즘을 사용하기 위해 congestion window라는 변수도 사용합니다. 이를 cwnd라 하겠습니다. congestion window는 송신 측이 트래픽을 전송할 수 있는 속도에 제약을 가합니다. 특히, 수신 측에 있는 ACK를 받지 않은 데이터 양이 min(cwnd, rwnd)를 넘지 않게 합니다. 따라서 수식은 다음과 같아집니다. LastByteSent - LastByteAcked <= min(cwnd, rwnd).
Congestion control 설명에 집중하기 위해 이제부터 TCP receiver buffer 크기는 receive-window를 무시해도 될 만큼 충분히 크다고 가정하겠습니다. 따라서 송신 측이 ACK 답을 받지 않은 데이터의 양은 오직 cwnd로만 좌우됩니다. 또 한, 송신 측은 항상 보내야 할 데이터가 있다고 가정합니다.
위 가정들은 통해 간접적으로 송신율을 제한합니다. 송신율이 제한된다는 것을 확인하기 위해 패킷 손실과 전송 지연이 무시할 수 있을 만큼 작은 커넥션을 상상해 보겠습니다. 그러면, 모든 RTT 초반에는 송신 측의 송신 제한은 cwnd bytes 입니다. RTT 마지막에는 ACK를 받습니다. 따라서 송신율은 대략 cwnd/RTT bytes/sec 입니다. 따라서 cwnd 값을 조정해서 송신측의 송신율을 조정할 수 있습니다.
이제 2번 질문에 대한 해결방식을 보겠습니다. 타임 아웃 또는 중복된 ACK를 세 번 받았을 때를 송신 측의 "loss event"라 정의하겠습니다. 혼잡이 심해지면 경로에 존재하는 임의의 라우터의 버퍼에서 오버플로우가 발생해 데이터그램이 버려지게 됩니다. 이렇게 버려진 데이터그램은 송신 측에서 loss event가 발생하게 합니다. 이를 통해 송신 측은 자신과 수신측 경로에 congestion이 있음을 알 수 있습니다.
만약 혼잡으로 인한 패킷 손실 없이 정상적으로 ACK가 도착한다면, 송신측은 ACK를 이용해 congestion window size를 올립니다. 따라서 ACK가 도착하는 속도에 따라 congestion window 크기가 커지는 속도가 달라집니다.
cwnd를 이용해 congestion control을 한다는 것을 알았지만 너무 빠르게 cwnd를 증가시키면 congestion이 발생하고 너무 느리게 증가시키면 밴드폭을 모두 사용할 수 없게 됩니다. 따라서 TCP는 Congestion control을 위한 다음과 같은 몇 가지 가이드 원칙을 제공합니다.
1. 세그먼트 손실은 congestion을 의미하므로 TCP는 송신율을 낮추어야 합니다.
2. ACK가 응답으로 왔다면, 이는 수신 측에게 패킷이 잘 도착했다는 의미이므로 송신 측은 송신율을 높일 수 있습니다.
이제 TCP congestion-control 알고리즘을 살펴보겠습니다. congestion-control 알고리즘은 3 가지 컴포넌트로 이루어져 있습니다. 이들은 각각 (1). slow start, (2) congestion avoidance, (3) fast recovery입니다. slow start와 congestion avoidance는 TCP의 필수 요소이며 수신된 ACK에 따라 cwnd 크기를 늘리는 방식에 차이를 둡니다. slow start의 cwnd 증가 속도가 congestion avoidance보다 빠릅니다. fast recovery는 사용하기를 추천하지만 필수는 아닙니다.
Slow Start
TCP 커넥션이 시작되면 cwnd 값이 1 MSS부터 시작합니다. 따라서 초기 전송률은 약 MSS/RTT가 됩니다. 가용 밴드폭이 MSS/RTT보다 크기 때문에 송신 측은 가용 밴드폭이 어느 정도인지를 빠르게 찾을 수 있어야 합니다. 따라서 slow start에서는 전송률을 매 RTT 마다 두 배씩 증가시킵니다. 즉, 지수적으로 증가합니다.
하지만 slow start가 매번 지수 증가를 하는 것은 아닙니다. 다음과 같은 몇 가지 상황에서는 더 이상 지수증가를 하지 않습니다.
1. 타임아웃에 의한 loss event가 발생했다면 TCP 송신 측은 cwnd 값을 1로 변경하고 slow start 프로세스를 다시 시작한다. 이때 ssthresh(slow start threashold) 값을 cwnd/2로 줄인다.
2. cwnd 값이 ssthresh 값에 도달했을 때 slow start를 중지합니다. ssthresh 값은 혼잡이 발생했을 때의 cwnd 값의 절반에 해당하기 때문에 cwnd 값이 ssthresh값과 같아진 상황에서 지수증가를 하는 것은 무모한 선택입니다. 따라서 slow start를 중지하고 congestion avoidance mode로 전환합니다. congestion avoidance mode에서는 cwnd를 조금 더 조심스럽게 증가시킵니다.
3. 중복된 ACK를 3번 받았을 때 slow start를 중지합니다. 이때는 TCP가 빠르게 패킷을 재전송하고 fast recovery 상태로 전환됩니다.
TCP congestion control 프로세스를 FSM로 보면 다음과 같습니다.
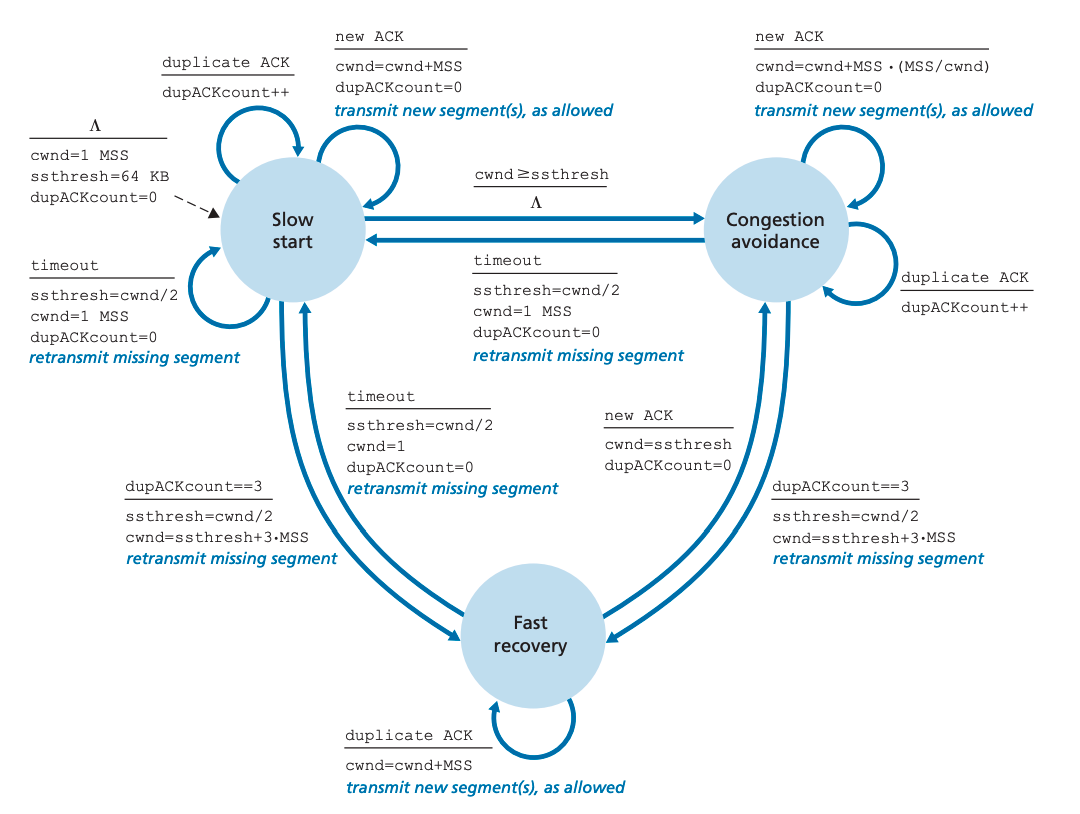
Congestion Avoidance
Congestion Avoidance가 되면 RTT 한 번당 cwnd를 두 배씩 늘리는 대신 1 MSS씩 선형적으로 증가합니다. Congestion-avoidance 알고리즘은 slow start에서 timeout이 발생했을 때와 같은 동작을 합니다. loss event 발생 시 cwnd는 1 MSS로 변경되고 ssthresh는 cwnd/2와 같은 값으로 변경됩니다. 그러나 loss event가 3번의 ACK 중복 수신으로 인해 발생할 경우는 지속적으로 세그먼트를 송신합니다. 이 경우 TCP는 cwnd를 절반으로 줄이고 3번의 ACK 중복 수신으로 인한 3 MSS 값을 더하고 ssthresh 값을 cwnd/2로 바꾼 뒤 fast-recovery 상태로 전환합니다.
Fast Recovery
Fast recovery 상태에선 누락된 세그먼트에 대한 중복된 ACK 하나당 cwnd를 1 MSS 씩 증가시킵니다. 그렇게 TCP가 누락된 세그먼트 위치에 왔다면 cwnd값을 ssthresh값과 같이 만들고 congestion-avoidance 상태에 진입합니다. 만약 타임아웃이 발생했다면 slow start와 congestion avoidance에서 타임아웃이 발생한 것과 같은 동작을 합니다. cwnd 값은 1 MSS가 되며 ssthresh는 cwnd/2 값이 됩니다.
Fast Recovery는 필수가 아닙니다. 초기 TCP 버전인 TCP Tahoe는 타임아웃이나 ACK 3번 중복 수신으로 인한 loss event가 발생하면 무조건 congestion window를 1 MSS로 줄이고 slow-start에 진입했습니다. 그러나 조금 더 최신 전인 TCP Reno는 fast recovery를 지원합니다. 아래 그래프는 TCP Reno와 Tahoe에 대한 congestion window 변화 추이입니다.

TCP Congestion Control: Restrospective
커넥션 시작 시 slow start를 무시하고 손실이 3번의 ACK 중복에 의해 발생했다고 가정하겠습니다. TCP congestion control은 RTT당 cwnd를 1 MSS씩 선형적으로 증가시키고 3번의 ACK 중복이 발생하면 cwnd를 절반으로 줄입니다. 따라서 TCP Congestion Control은 additive-increase, multiplicative-decrease(AIMD)라고도 합니다.

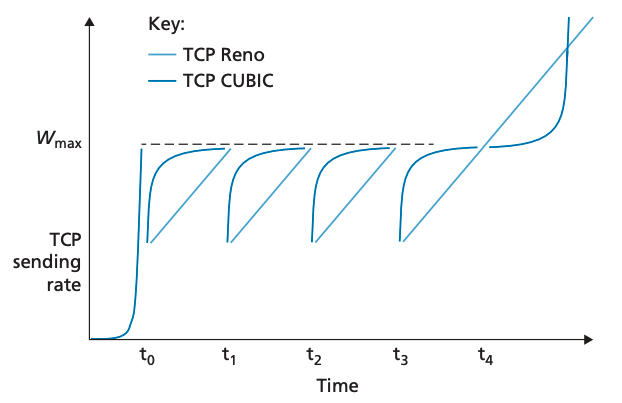
TCP CUBIC
위 방식들은 모두 패킷 손실이 나면 ssthresh 값을 절반으로 줄이고 cwnd값을 천천히 증가시킵니다. 그러나, 만약 혼잡으로 인한 패킷 손실 지점이 그게 변동이 없다면 이전 손실 지점 까지는 빠르게 cwnd를 증가시키는 것이 더 효율적입니다. 이 방식을 TCP CUBIC이라 합니다.
TCP CUBIC은 TCP Reno와 거의 유사합니다. congestion window는 오직 ACK를 받았을 때만 증가하며 slow start와 recovery phase는 TCP Reno 동작과 같습니다. 다만, congestion avoidance 상태의 동작이 다릅니다. TCP CUBIC의 congestion avoidance 동작은 다음과 같습니다.
1. Wmax를 마지막으로 손실이 발생한 지점의 congestion window 크기라 하겠습니다. 그리고 K를 TCP CUBIC이 추후 Wmax에 도달했을 때의 윈도우 크기라 하겠습니다.
2. CUBIC은 현재 시간 t가 증가함에 따라 K까지 세제곱 함수꼴로 congestion window를 증가시킵니다. 따라서 t가 K에서 멀수록 증가폭이 더 큽니다. 이를 통해 직전에 손실이 난 곳까지 빠르게 송신율을 증가시킵니다. 그 후, Wmax에 도달하면 밴드폭을 조사합니다.
3. t가 K보다 크지만 여전히 K보다 가까울 때는 congestion window 증가폭이 크지 않습니다. 하지만 일정 수준을 벗어나면 congestion window 크기를 빠르게 증가시켜 새로운 Wmax 지점을 찾습니다.
위 과정을 그래프로 나타내면서 TCP Reno와 비교해 보면 다음과 같습니다.
Macroscopic Description of TCP Reno Throughput
TCP Reno 커넥션이 길어지면 평균 수율이 어떻게 되는지 살펴보겠습니다. 이번 설명에서는 timeout이 발생하는 slow-start 과정을 생략하고 살펴보겠습니다. 윈도 크기가 w bytes 이고 RTT가 RTT seconds라면 TCP 전송율은 약 w/RTT입니다. TCP는 밴드폭을 알기 위해 w를 loss event가 발생할 때까지 RTT 한번 당 1MSS씩 증가시킵니다. W를 loss event가 발생했을 때의 혼잡 윈도우 크기라 하겠습니다. RTT와 W가 커넥션 기간 동안 대동소이 하다고 가정하면, TCP 전송률은 W/(2 RTT) ~ W/RTT 사이입니다.
위 가정은 안정 상태의 TCP 행동에 대한 간단한 거시적 모델을 만들 수 있게 해 줍니다. 네트워쿠 혼잡이 W/RTT에 달했다면 패킷에 손실이 발생합니다. 그러면 송신율을 절반으로 떨어지고 RTT 한번 당 MSS/RTT 만큼 W/RTT에 도달할 때까지 congestion window 크기가 증가합니다. 이 프로세스는 반복적으로 실행되며 수율은 W/(2 RTT) ~ W/RTT 사기에서 선형적으로 증가합니다. 따라서 커넥션의 평균 수율은 (0.75 * W)/RTT 입니다.
출처: Computer Networking A top-down approach 8th edition - James F .Kurose, Keith W. Ross