IP 주소의 기본
브라우저는 생성한 메시지를 네트워크에 송출하는 기능을 제공하지 않는다. 따라서 이를 OS에 위임한다. 이 때, OS는 도메인명이 아닌 IP를 사용하므로 브라우저는 HTTP 메시지를 만든 후 도메인명을 통해 IP를 찾아야 한다.
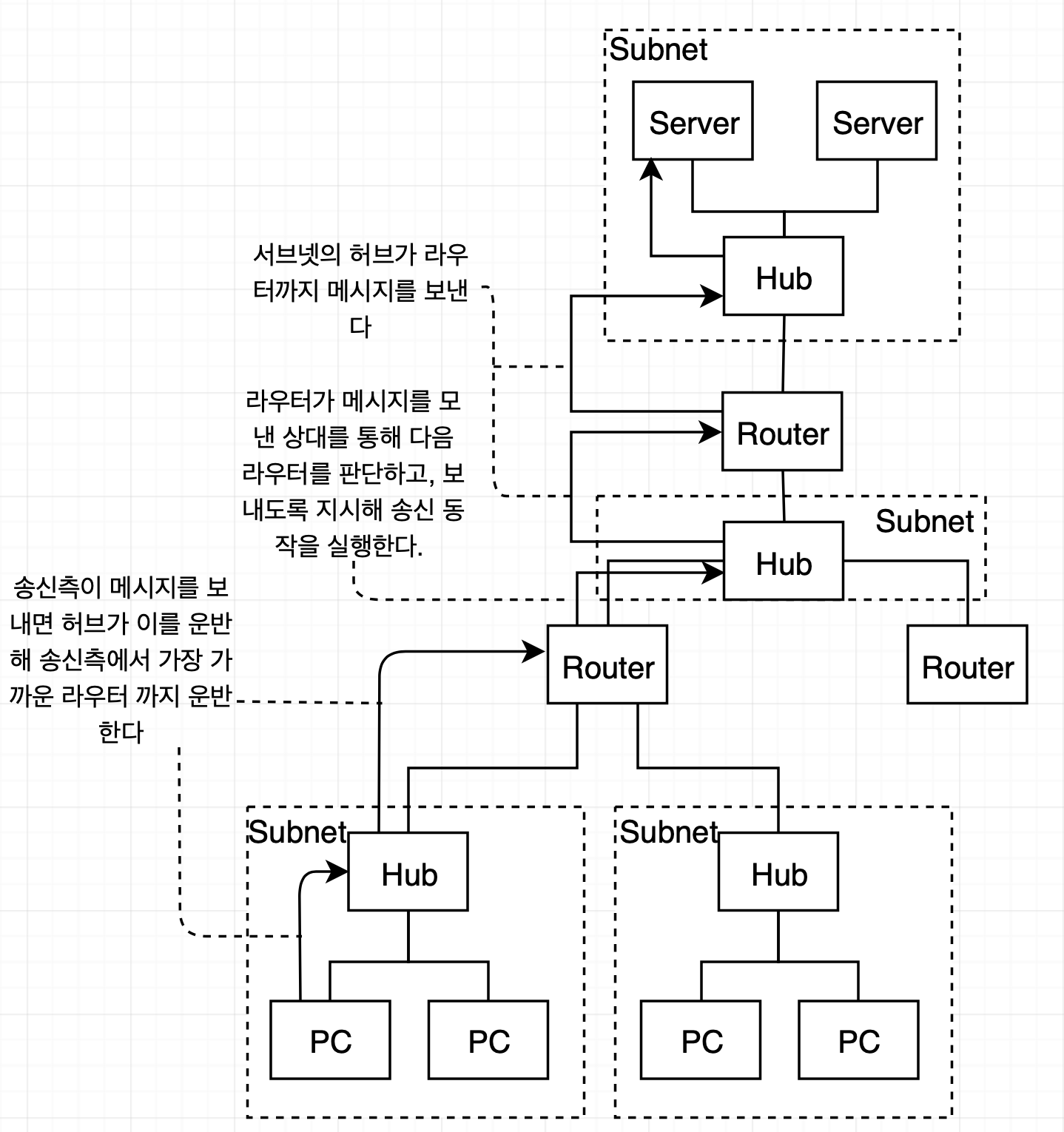
TCP/IP 네트워크는 서브넷이라는 작은 네트워크를 라우터로 연결해 전체 네트워크를 완성한다. 여기서의 서브넷은 허브에 몇 대의 PC가 접속된 것이다. IP는 네트워크 번호와 호스트 번호로 나뉘어져 있다. IP의 네트워크 번호는 서브넷에 할당되고, 호스트 번호는 컴퓨터에 할당된다.
실제 IP는 IPv4 기준으로 32비트이다. 이를 8비트(1바이트)씩 점으로 구분해 10진수로 표기한다(ex - 10.11.12.13). IP 주소 규칙은 오직 네트워크 번호와 호스트 번호 두 가지를 합쳐서 32비트가 되야 한다는 것만 결정되 있다. 따라서 네트워크 구축 시 사용자가 직접 네트워크 번호와 호스트 번호의 범위를 결정해야 한다. 정한 내역은 필요에 따라 IP에 덧붙이며 이를 넷마스크라 한다.
IP 주소와 함께 넷마스크를 표기하는 방식은 다음과 같다.
IP 주소 본체와 같은 방법으로 네트워크를 표기하는 방법

네트워크 번호의 비트 수로 넷마스크를 표기하는 방법(CIDR)

서브넷을 나타내는 주소
호스트 번호 부분의 비트가 모두 0이면 각 컴퓨터의 IP가 아닌 서브넷 자체를 나타낸다.

서브넷의 브로드캐스트를 나타내는 주소
호스트 번호의 비트가 모두 1이면 서브넷 전체에 대한 브로드캐스트를 나타낸다. 브로드캐스트는 서브넷에 있는 기기 전체에 패킷을 보낸다.

넷마스크는 IP 주소에서 32비트 부분의 디지털 데이터이다. 왼쪽에 1이 나열되고 오른쪽에 0이 나열된다. 여기서 1인 부분은 네트워크 번호를 나타내고, 0인 부분은 호스트를 나타낸다. IP주소와 호스트 번호를 2진수로 나타내고 이들을 AND 논리 연산하면 네트워크 번호와 호스트 번호를 알아낼 수 있다.

엑세스 대상의 서버까지 메시지를 운반할 때 액세스 대상의 위치를 판별하고 운반하기 위해 IP 주소를 사용한다.
도메인명과 IP 주소를 구분해 사용하는 이유
TCP/IP 네트워크는 IP 주소로 통신 상대를 결정한다. 따라서 URL에서 서버명을 IP로 전환하지 않기 위해 IP를 직접 사용하는 것이 효율적이라고 생각할 수 있다. 하지만 IP 주소를 일일히 기억하기는 어렵다.
그러면 IP대신 서버명 자체로 상대를 지정하는 것은 어떨까? 즉, 서버명을 IP로 변환해 상대를 식별하는 것이 아닌, 서버명 자체로 상대를 결정하는 것이다 . 이는 실행 효율 측면에서 좋지 않다. IP는 32비트로 한정되 있는 반면, 도메인명은 수십바이트에서 255바이트의 범위를 가진다. 따라서 취급해야 하는 문자가 늘어남에 따라 라우터에 부하가 발생한다. 결국 네트워크 속도 저하를 야기한다. 고성능 라우터 역시 속도에 한계가 있으며 네트워크 속도 향상에 따라 데이터 양도 증가했다. 따라서 고성능 라우터를 사용하는 것 역시 해결책이 아니다.
이름과 IP를 상호 매핑하기 위해 필요한 것이 DNS이다.
Socket 라이브러리가 IP 주소를 찾는 기능을 제공한다
IP 주소를 조사하기 위해선 도메인 이름을 가지고 DNS 서버에 조회하면 된다. 이를 풀어말하면, DNS 서버에 요청을 보내는 클라이언트가 존재하고, DNS 서버에 조회한다는 것은 이 서버에 요청을 하고 응답을 받는다는 것이다. 여기서 DNS 클라이언트에 해당하는 것을 DNS 리졸버라 한다. 리졸버는 DNS의 원리를 사용해 IP 주소를 조사하며 이를 네임 리졸루션(name resolution)이라 한다.
리졸버는 소켓 라이브러리에 존재하는 부품화한 프로그램이다. 소켓 라이브러리는 OS에 포함된 네트워크의 기능을 애플리케이션에서 호출하기 위한 부품을 모아놓은 것이다.
리졸버를 이용해 DNS 서버를 조회한다
소켓 라이브러리는 말 그대로 라이브러리이다. 따라서 소켓 라이브러리 안헤 있는 리졸버를 사용하기 우해서는 단순히 리졸버의 프로그램명(gethostbyname)과 웹 서버의 이름을 쓰기만 하면 리졸버를 호출할 수 있다. 소켓 프로그래밍에서 gethostbyname으로 DNS서버와 통신해 ip를 알아낼 수 있는 코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <errno.h>
#include <netdb.h>
#include <arpa/inet.h>
int DNSLookUp(char* hostname, char * ip) {
struct hostent* H;
struct in_addr** AddrList;
if ((H = gethostbyname(hostname)) == NULL) {
herror("gethostbyname() error");
return 1;
}
AddrList = (struct in_addr **) H->h_addr_list;
for (int i = 0; AddrList[i] != NULL; i++) {
strcpy(ip, inet_ntoa(*AddrList[i]));
return 0;
}
return 1;
}
int main(int argc, char* argv[]) {
if (argc < 2) {
printf("No hostname was provided to resolve");
exit(1);
}
char* hostname = argv[1];
char ip[100];
DNSLookUp(hostname, ip);
printf("%s has been resolved to %s\n", hostname, ip);
return 0;
}
|
cs |
리졸버 내부의 작동
애플리케이션에서 호출된 리졸버는 다음과 같이 작동한다.
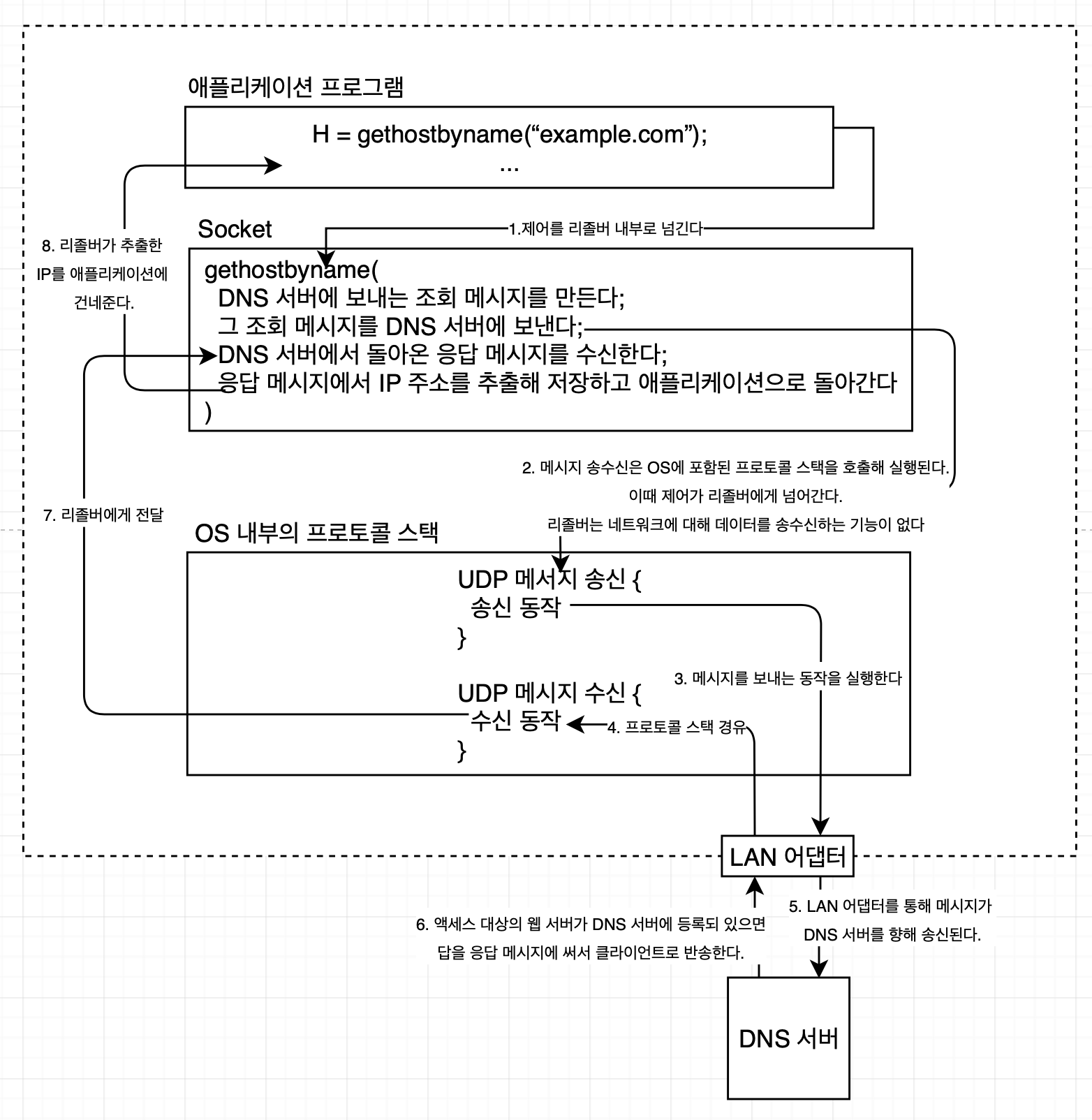
위 과정을 보면 IP를 얻기 위해 여러 계층을 이동한다. 컴퓨터의 내부는 다층 구조로 되어 있다. 그리고 각 층은 서로의 역할을 분담한다. 그때문에 상위 계층에서 일을 의뢰하면, 그 일을 스스로 전부 실행하지 않고, 하위 계층에 실행을 의뢰한다.
DNS 서버에 요청을 할때도 DNS 서버의 IP가 필요하다. 이는 TCP/IP 설정 항목 중 하나로 컴퓨터에 미리 설정되 있다. 현재 내 맥에 설정된 DNS IP는 다음과 같다.
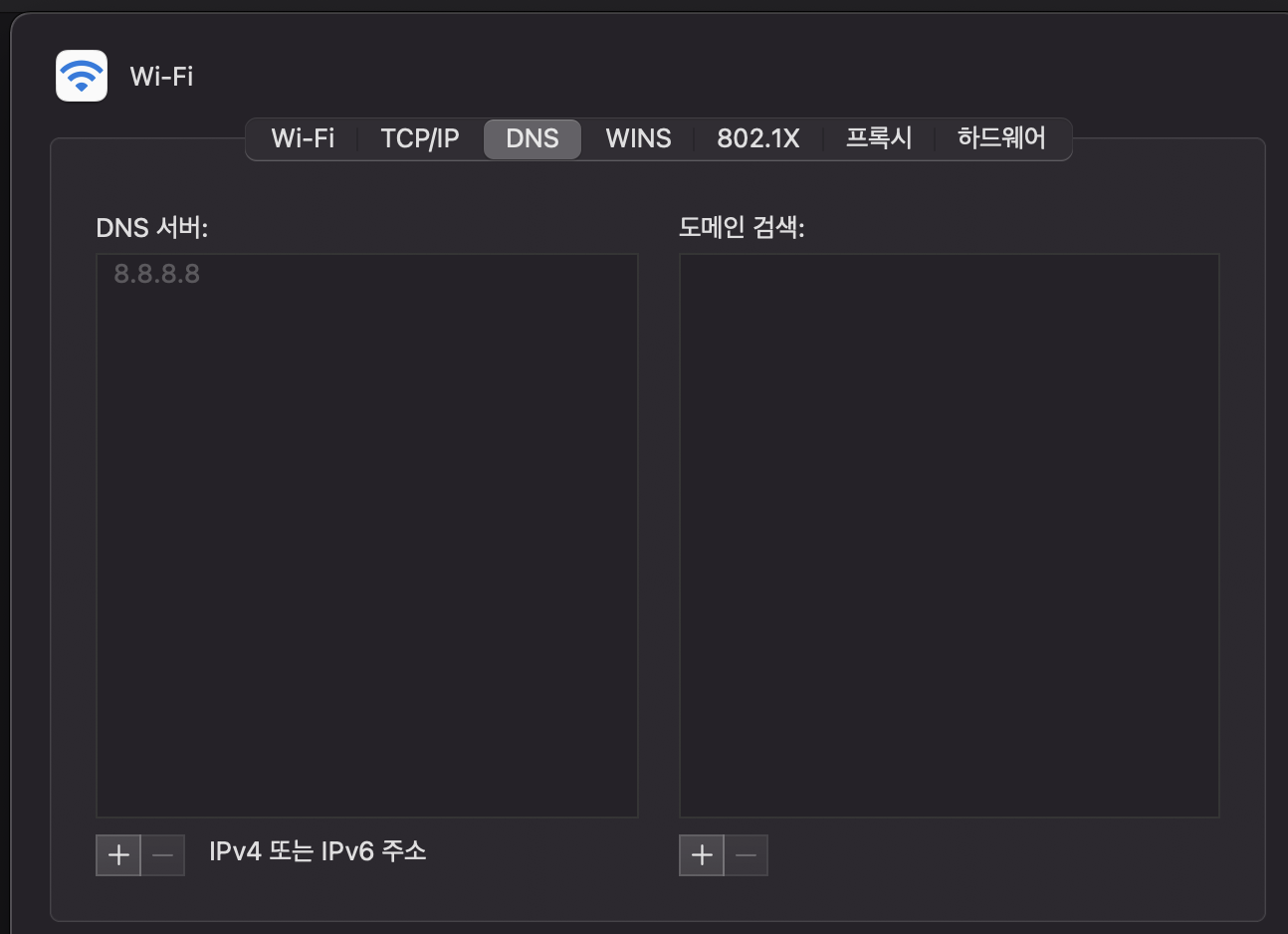
출처 - 성공과 실패를 결정하는 1%의 네트워크 원리