분산 시스템은 분산 컴퓨팅(distributed computing) 또는 분산 데이터베이스(distributed databases)로 알려져 있다. 하나의 분산 시스템은 서로 다른 머신들에 위치해 있는 독립된 컴포넌트들의 묶음이다. 이 묶음은 하나의 공통된 목적을 달성하기 위해 서로 메시지를 주고받는다.
분산 시스템은 엔드포인트에서는 하나의 인터페이스 처럼 나타내어진다. 분산 시스템은 하나의 시스템에서 장애가 발생해도 서비스의 가용성에 영향을 미치지 않는것 처럼 리소스를 극대화 할 수 있다.
현대의 분산 시스템은 갖은 물리적 머신에서 동작하지만 독립적으로 동작하고(autonomous processes) 상호작용을 위해 메시지를 주고 받기도 한다.
분산 시스템에서 요구되는 기능
Resource Sharing: H/W, S/W와는 관련없이 데이터는 공유될 수 있다.
Openness: 개발되고 공유되도록 설계된 소프트웨어가 얼마나 개방적인가.
Concurrency: 여러대의 머신들이 같은 기능을 동시에 프로세싱할 수 있는가.
Scalability: 많은 머신들로 확장할때 프로세싱능력이 어떻게 증가하는가.
Fault tolerance: 얼마나 쉽고 빠르게 시스템의 장애를 찾고 복구할 수 있는가.
Transparency: 한 노드가 시스템의 노드를 찾고 통신하기 위해 얼마나 많은 액세스 권한을 갖어야 하는가.
분산 시스템 예시
Networks: 1970년대에 이더넷의 발명과 LAN의 탄생됬다. 초기의 컴퓨터들은 로컬 IP 주소로 다른 시스템들에게 메시지를 전송할 수 있었다. Peer-to-peer 네트워크의 발전, 이메일과 인터넷의 발은 모두 분산 시스템의 예시이다.
Telecommunication networks(통신망): 전화와 셀룰러 네트워크는 분산시스템의 한 예시이다. 전화 통신은 약 한세기 이전에 탄생했으며 초기 peer-to-peer네트워크의 예시이기도 하다. 셀룰러 네트워크는 셀이라 불리는 영영엣 물리적으로 분포된 기지국을 가진 분산 네트워크이다.
Distributed System Archiatecture
분산 시스템은 반드시 모든 컴포넌트들(머신, 하드웨어, 소프트웨어)이 연결된 하나의 네트워크를 가져야 하고 이를 통해 메시지로 서로 커뮤니케이션을 할 수 있어야 한다. 이 네트워크는 하나의 IP 또는 케이블들로 연결되 있어야 한다. 머신들 사이에서 전송되는 메시지들은 이스템이 공유하길 원하는 데이터의 형식(파일, 객체 등)을 포함하고 있어야 한다. 메시지를 전송, 수신, 승인 또는 실패에 대해 노드가 재시도하는 방법은 분산 시스템에서 중요한 기능이다. 분산 시스템은 확장에 필요한 서비스와 애플리케이션, 새로운 머신을 추가하고 관리해야 하는 필요성에 의해 만들어졌다. 분산 시스템을 디자인 할때 고려해야할 주된 trade-off는 복잡도와 퍼포머스이다.
분산 시스템의 종류
Client-server:
초기 분산 시스템 아키텍처는 데이터베이스, 웹 서버 같은 공유 자원으로 서버를 구성했다. 이는 여려 클라이언트들이 존재한다. 이 클라이언트들은 언제 공유된 리소스를 사용할지, 어떤식으로 사용할지, 어떻게 데이터를 바꿀지 등을 결정한다.
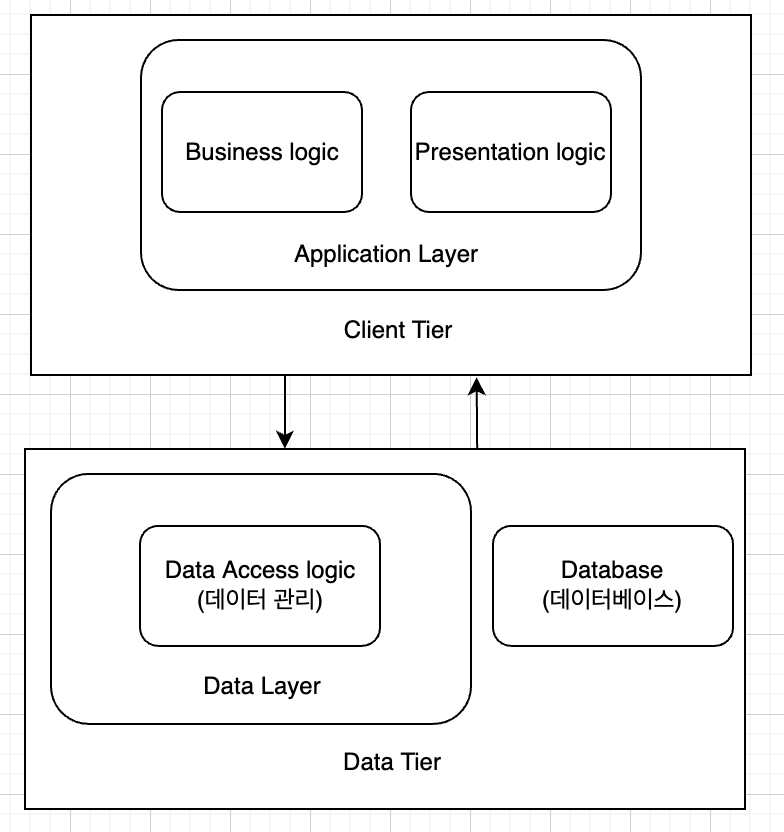
Three-tier:
이 아키텍처에서는 유저가 결정을 내리지 않아도 중간 계층에 의해 의사를 결정할 수 있다. 초기 웹 애플리케이션이 이에 해당된다. 이 중간 계층은 에이전트라 불릴 수 있고 클라이언트들로 부터 요청들을 받는다. 이런 중간 계층은 stateless일 수 있고 데이터를 처리해 서버로 넘긴다.

Presentation Tier(Client Tier):
응용 프로그램의 최상위에 위치하고 있고 이는 서로 다른 층에 있는 데이터 등과 커뮤니케이션을 한다. Presentation tier는 상요자 인터페이스를 지원하며 front-end로 불리기도 한다. 이 티어에서는 비즈니스로직과 데이터 관리 코드를 포함하면 안된다.
Application Tier:
비즈니스 로직 계층 또는 트랜잭션 계층이라고도 한다. 애플리케이션 티어는 클라이언트 요청에 대해 서버처럼 동작한다. 어떤 데이터가 필요한지를 결정하고, 메인프레임 컴퓨터 상에 위치하고 있을 세번째 계층의 프로그램에 대해서는 클라이언트 처럼 행동한다. 애플리케이션 티어는 미들웨어 또는 백엔드로 불린다.
Data Tier:
데이터 계층은 DB와 DB를 엑세스해 읽거나 쓰는 것을 관리하는 프로그램을 포함한다. 데이터 티어는 백엔드 또는 파일 시스템을 접근하고 관리하며 백엔드라고 불리기도 한다.
Multi-tier:
엔터프라이스 웹 서비스가 처음으로 n-tier 또는 multi-tier라는 시스템 아키텍쳐를 만들었다. 이는 비스니스 로직을 포함하고 데이터 베이스 로직과 프레젠테이션 로직(클라이언트, 사용자 인터페이스)을 포함하는 애플리케이션 서버를 대중화 시켰다. 이 로직은 클라이언트와 서버를 분리시켜서 애플리케이션과 DB가 분리되어 있기 때문에 DB변경이 용이하다는 장점을 가지고 있다.
Peer-to-Peer:
이 아키텍쳐는 중앙 집중화된 머신이 존재하지 않는다. 이 아키텍쳐를 사용하는 머신들은 서버이자 클라이언트이다. 블록체인이 이 예시이다.
* tier는 컴포넌트들을 물리적으로 분리 함을 의미한다. 그에 반해 layer는 컴포넌트들을 논리적으로 분리한다는 의미이다.
분산 시스템의 장점
분산 시스템의 궁극적인 목표는 확작성, 퍼포먼스, 애플리케이션의 고가용성(High availability)을 가능케 하는 것이다.
1. 수평적 확장이 가능하다 - 머신들을 필요할때 추가시킬 수 있다.
2. 낮은 latency - 머신을 물리적으로 유저와 가깝에 위치 시킴으로서 지연을 낮춘다
3. fault tolerance - 하나의 서버가 다운되면 다른 서버들이 그 일을 처리할 수 있다.
분산 시스템의 단점
복잡성은 분산 시스템의 가장 큰 단점이다. 많은 머신들이 존재할 수록 더 많은 메시지와 더 많은 데이터들을 서로 주고 받게 된다. 이는 다음과 같은 이슈들을 발생시킨다.
1. 데이터 통합, 일치 - 데이터와 애플리케이션의 상태를 분산시스템에서 동기화 하기 까다롭다. 특지 노드들이 시작할때, 멈출때, 실패했을때는 더욱 그렇다.
2. Network and communication failure - 메시지들이 올바른 노드에 도달하지 않거나 순서가 틀릴경우 통신과 기능 장애를 초래할 수 있다.
3. Management overhead - 더 많은 모니터링, 로깅, 로드 밸런싱이 가식성을 위해 분산 시스템의 연산과 실패에 투입되어야 한다.